Introduction
Welcome to my wiki, this is where I document my learning, including notes on certifications and courses I take, programs I use and workflows I re-use.
I believe in creating a central repository for your knowledge, instead of relying on external services to consume tidbits of information. By collating and documenting what I learn, it helps my synthesise information and have persistent reference points written and maintained by me.
It is built using mdBook, which is a really great CLI for generating books/wikis from markdown files.
AWS Solutions Architect
Amazon Web Servbices (AWS) is a cloud provider.
It provides servers and services on demand that can easily scale.
It's in direct contrast to on-premise solutions that require ordering servers and setting them up manually.
It powers a lot of well known websites, like Netflix.com, which rents all their servers from AWS.
Facts
- AWS has 90b in revenue
- 31% of cloud market
- 1m active users
Use cases
Almost any use case you could want.
- Hosting websites
- Backups and storage
- Big data analytics etc etc
Projects
A list of project to complete as part of this course:
- norfolkgerringong static website hosting with S3
You can check out the AWS infrastructurnd regions here: https://aws.amazon.com/about-aws/global-infrastructure/regions_az/
It's a global infrastructure, meaning we can deploy apps to be global
Regions
Regions have names, e.g us-east-1
A region is a cluster of data centres
Most services are region scoped.
Some factors in choosing regions could be:
- Compliance
- Latency
- Service availability (some regions don't have certain services)
Each region has 'zones', which are separate data centres from each other and are isolated from disasters.
Not all services are available in all regions, see here: https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/?p=ngi&loc=4
Identity Access Management (IAM)
This is a global service.
A root account is created first, but it shouldn't be used thereafter, we should create new users instead.
Users can be grouped.
Groups only contain users, not other groups.
A user can be in multiple groups, and users don't need to be in groups.
IAM permissions
User permissions are defined as policies, which are JSON documents that manage user permissions.
AWS follows the least privilege principle, meaning you don't give more permissions than a user needs.
Policy inheritence
User inherit policies from the team(s) they belong to. But you can also create an inline policy, which is a policy just for one user, assuming they don't belong to a group.
If a user belong to 2 groups, they will inherit the permissions from both groups.
IAM Policy
Consist of:
- Version
- ID
- Statement
Statements consist of ids, effects, principals, actions and resources.
Protecting your account
There are two main ways to protect an account, a password policy and Multi Factor Authentication (MFA)
Password policy
This policy defines what type of password users can store (character and length etc) but also how often the password resets, whether the user can use the same password more than once etc.
MFA
This is an additional step during login and requires a user to type in an additional code once they have submitted their password. There are four ways to do this:
- A virtual device like Google Authenticator
- A security key (U2F) device
- Hardware key fob
- Hardware key fob (
Protecting your account
There are two main ways to protect an account, a password policy and Multi Factor Authentication (MFA)
Password policy
This policy defines what type of password users can store (character and length etc) but also how often the password resets, whether the user can use the same password more than once etc.
MFA
This is an additional step during login and requires a user to type in an additional code once they have submitted their password. There are four ways to do this:
- A virtual device like Google Authenticator
- A security key (U2F) device
- Hardware key fob
- Hardware key fob (for AWS GovCloud US)
IAM roles for services
Sometimes we need services to perform actions for us. For example we can have an EC2 instance and we need that instance to manage our AWS account.
To do this we use IAM Roles.
For example, we create a role that is trusted by a service, such as EC2. This role may have permissions like accessing IAMReadOnlyAccess. Now our EC2 instance can read our IAM.
Security tools
IAM Credentials Report
This lists all users and their credentials.
Access Advisor
This lists individual users and the permissions granted to them, including them they last accessed the services. This allows you to understand which services the users has access to and which you might want to revoke.
Best practices for IAM
- Don't use root account except for setup
- 1 physical users should = one AWS user
- Assign users to groups and assign permissions to groups
- Create strong pw policy
- Use and enforce MFA
- Create Roles for giving permissions to AWS services
- Use access keys for programmatuc access
- Audit permissions using Access Advisor
- Never share IAM user & access keys
Overview
- Users are physical users and each have their own access
- Groups contain users only
- Policies are JSON docs with permissions
- Roles give features AWS access
- Security: MFA + p/w policy
- CLI/SDK are programmatic acesss
- Access keys : give programmatic access
- Audit users with credential reports and access advisor
AWS CLI, SDK and Cloud Shell
There are 3 ways to access AWS:
- The web console
- AWS CLI
- AWS SDKs
The CLI is open source and allows you to make operations from the command line.
The SDKs allow you to access AWS programatically through API calls using a set of language specific APIs, including: JS, Node, PHP, Python, .NET, Ruby, Java, Go, C++.
AWS CLI
You need to use an access token to setup the AWS CLI. You define access tokens per user and then user :
aws configure to create access for that user from the command line.
Cloudshell
You can use cloudshell in the AWS console as well.
This will automatically use the active user's credentials. It allows for :
- File downloads
- Uploads
- etc etc
It is only available in some regions, however.
EC2
An EC2 instance is just a virtual machine that you hire. It stands for Elastic Compute Cloud and is infrastructure as a service.
You can also:
- Store data on virtual drives
- Distribute load across machines
- Scale services
You can choose what you want your virtual machine to be and its power, including CPU, RAM, networking capabilities etc. You can also choose between Mac, Linux and Windows machines.
Bootstrapping
What the machine does at launch can be controlled using bootstrapping scripts
EC2 instance types
https://aws.amazon.com/ec2/instance-types/ https://instances.vantage.sh/ There are different types of EC2 instances, designed for different purposes. You can find them above.
Using m5.2xlarge as an example, the naming convention is:
- m: instance class, in this case m means general purpose
- 5: generation (AWS improves gens over time)
- 2xlarge: size, so the CPU and processing power
General purpose
Compute optimized
High performance with good CPU. Examples are of the C name
Memory optimized
High RAM. High performance for databases, cache stores, big unstructured data. An example are the R instances
Storage optimised
Good for high, sequential read and write access to large data sets.
Examples:
- Databases
- Cache for in memory dbs
- Online transactioning systems
- Distributed filed systems
EC2 instance firewalls
You can control who can access the EC2 instance and how your EC2 instance interacts with the internet using security groups.
Security groups
Security groups contain allow rules that can reference IPs or groups that can access instances. Therefore they act as a firewall on EC2 instance, by regulating:
- Port access
- Authorised IP ranges
- Inbound traffic
- Outbound traffic

Groups:
- Can be attached to multiple insrtances
- Locked down to region/VPC combination
- Live outside Ec2 instances - they are their own standalone thing
- timeouts usually mean security group issue
- inbound traffic is blocked by default
- outbound traffic is authorised by default
- you can attach security groups to more than one instance
Ports
These are the ports you must know:
SSH
SSH is a CLI that can be used on Mac and Linux and Windows V > 10 (or PuTTy) below V10
EC2 instance connect also allows connection to your EC2 instances.
AWS gives you the user EC2-user already, so the SSH command to login to the server has the following components:
- ssh ec2-user@
- you need to use the .pem file (which contains a private key) using the -i flag (identity file flag)
The full command: ssh -i EC2Tutorial.pem ec2-user@44.201.88.145
With all EC2 instances, if you experience a timeout, either when using SSH or otherwise, it's usually a security group issue
EC2 instance connect
You can do all this in the browser, without managing keys by going to SSH Instance Connect.
IAM Roles for EC2 instances
You should always manage EC2 instance access through IAM roles, not by adding your credentials directly into the instance using aws configure as this data can be accessed by other users on the instance. So instead, attach an IAM Role to the EC2 instance and manage service access through role policies.
EC2 pricing
There is different EC2 pricing, which you can see below depending on what's needed:
{kind=link}
IPV4 vs 6
AWS will charge for IPV6 ip addresses that go over 750 hours a month. So if you have more than 1 ip address it's likely you will incur costs.
EC2 controls
There are a few ways to control the instances:
- Stop: data is kept intact for next start. OS has to boot and can take time
- Terminate: data and setup is lost
- Hibernate: RAM is preserved, OS is not stopped / restarted. RAM state is written to file in volume.
Hibernation helps for saving RAM state, boot up fast and want long running processes. Can be no longer than 60 days.
IPs
IPV4 vs IPV6
IPV4 are "classic" IP addresses, but they are running out, so the internet is moving to IPV6.
The IPV4 address we get with our EC2 instance will be enough.
The format is as follows: [0-255].[0-255].[0-255].[0-255] allowing for 3.6b IPV4 addresses
Private VS public IPs
Public IPs allow servers to be accessed via the internet. Whereas private IPs can only be accessed internally from the same network. Private networks can interact with the WWW using an internet gateway (proxy)
Private IPs can repeat, whereas public IPs cannot.
Elastic IPs
AWS allows Elastic IPs, which are static IP addresses you can keep and then port between services. So the IP remains static and can be applied to different services. AWS gives you 5 of these. Each can only be attached to an instance one at a time.
Avoid elastic IPs, instead register a DNS name to a random public IP. Or use a load balancer.
EC2 Placement Groups
Placement groups allow you to define where your EC2 instances are deployed on AWS infrastructure.
A placement group is either:
- A cluster: puts your instances in a low latency group in the same AZ. This helps with networking as instances are close to one another. Drawback is if the AZ fails, they all fail. use case: Good for big data jobs, apps that need low latency between instances.
- Spread: Think of this as opposite to clusters. Each instance is on different hardware across different AZs. This means reduced failure risk. Limited to 7 AZ per placement group. Use case: maximum high availability.
- Partition: spreads instances across different partitions within an AZ. Each partition represents a rack in AWS. Instances are distributed across different hardware racks and AZs in same region. use cases: Big data application, which are petition aware.

Route 53
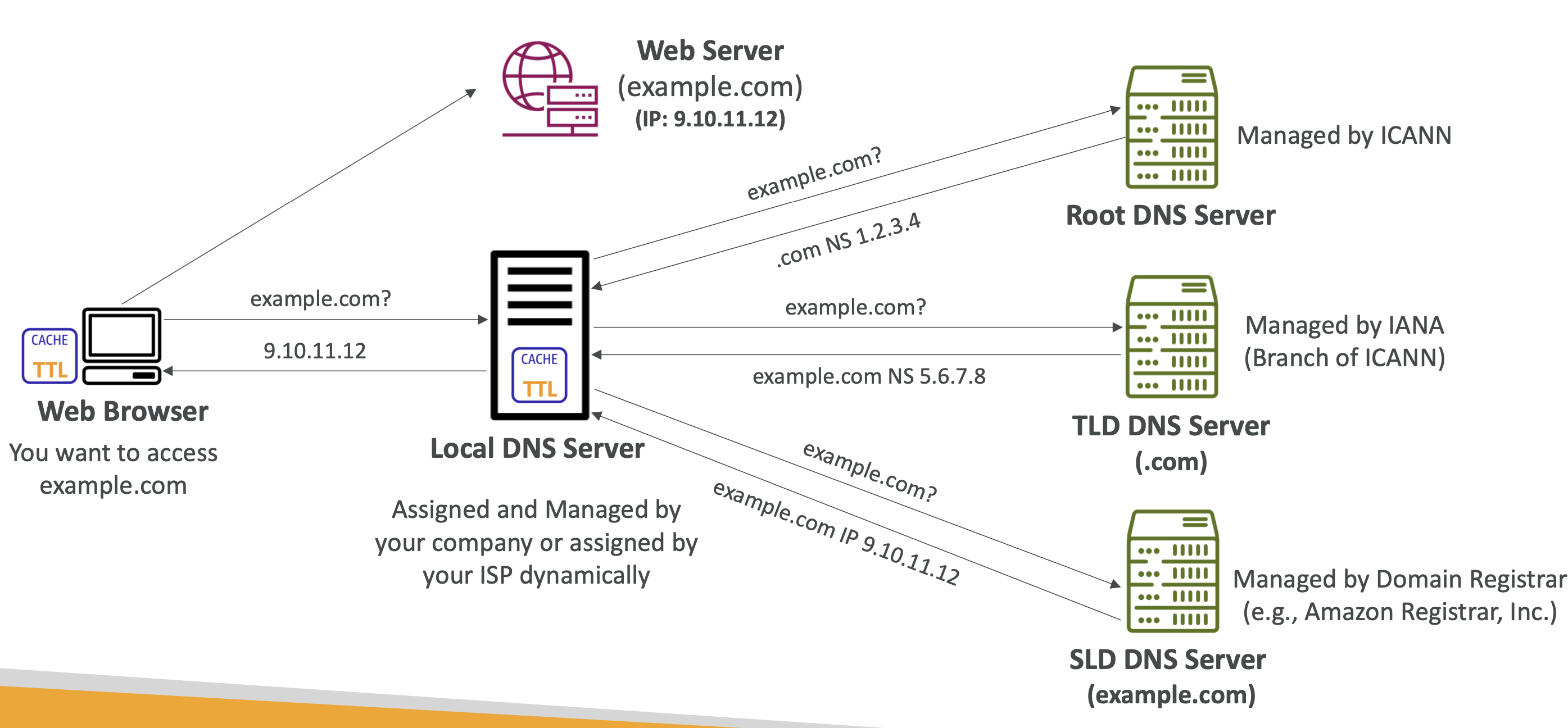
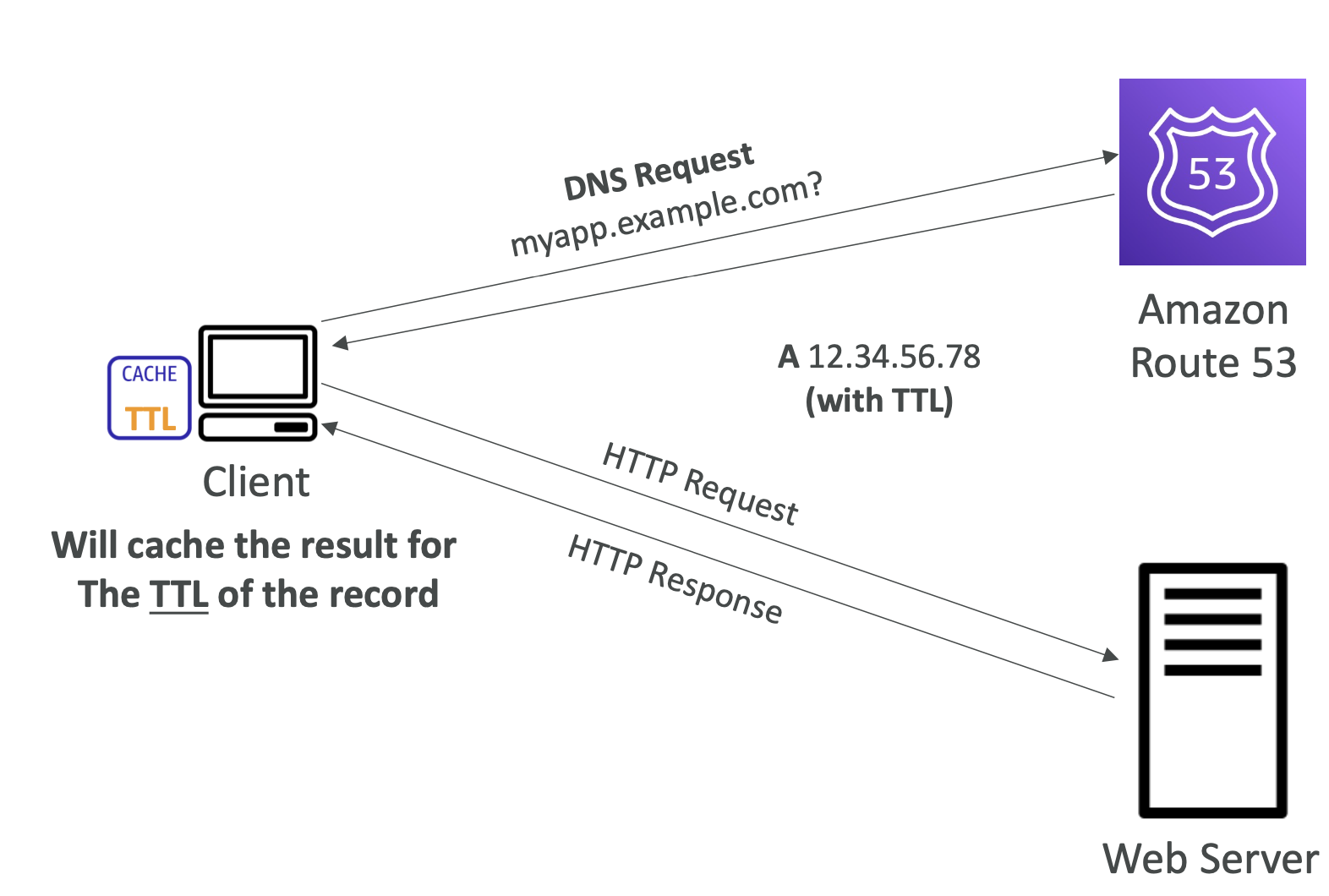
What is DNS?
Domain Name Servers (DNS) are a way to resolve website URLs to IP addresses.
For example translating www.google.com to it's IP address of 172.217.18.36.
URL breakdown
This is the breakdown of a URL:

How DNS works
The process of resolving an IP address takes many steps, including reaching out to many servers:
Amazon Route 53
This is Amazon's DNS service and domain registrar.
Requests to websites registered with Route 53 will go to Amazon's Route 53 DNS.
Route 53 DNS records
DNS records are instructions stored on DNS records that allow us to connect domain names to IP addresses. Route 53 is authoritative, meaning you have control over your DNS records.
Route 53 supports the following records:
- Must know: A / AAAA / CNAME / NS
- Advanced: CAA / DS / MX / NAPTR / PTR / SOA / TXT / SPF / SRV
Record types
- A: maps a domain name to an IPv4 address
- AAAA: maps a domain name to an IPv6 address
- CNAME: maps a hostname to another hostname. C stands for "canonical" and CNAMEs allow you to create aliases for your domain names. For example, you could point example.domain.com to domain.com to resolve the IP address, instead of to the IP address itself. The IP resolution will happen at domain.com
- NS: Name Servers for the hosted zone. This controls how traffic is routed for the domain.
Route 53 - Hosted Zones
Hosted Zones are containers that define how to route traffic to a domain and subdomains. For example you can have:
- Public Hosted Zones: records that define how to route public domain names
- Private Hosted Zones: records that define how to route private domain names
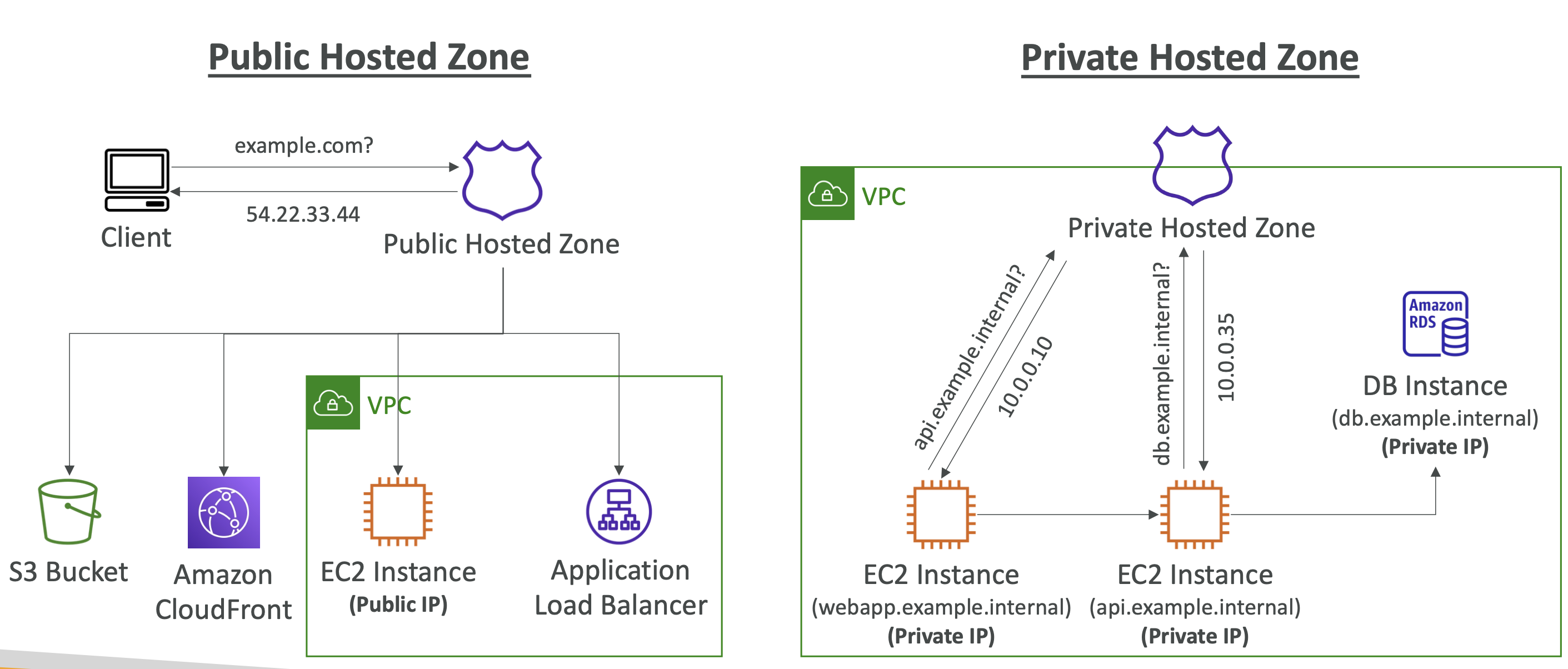
TTL (Time to live)
TTL is basically how long the client should cache DNS records. You can set TTL for each DNS record, which tells the browser to not make another DNS request once it has the record for that duration.
CNAME Vs Alias
CNAME
CNAME is a way to point one domain to another domain app.mydomain.com => blabla.amazon.aws.com, for example.
However, this only work for non root domains. mydomain.com wouldn't work, for example.
Alias
This points a hostname to an AWS resource mydomain.com to myalb.amazonaws.com.
Here we are pointing a root domain to an AWS resource.
This works for both root and non root domains.
Routing policy
The routing policy is the policy that defines how DNS responds to queries, so how the IP name is resolved for a domain name.
Simple routing
This just routed traffic to a single resouce. For example foo.example.com is routed to 11.22.33.44.
If there are multiple IP addresses for the same records, the client will randomly choose one.
- If alias is enabled, you can only specify one resource
- No health checks possible
Weighted routing
Weighted routing allows you to define a relative amount of traffic to be routed to a resource.
AWS will apply a percentage of traffic to that resource correlating to the weight set.
For example:
- weighted.example.com (some ip) -> 10 (some ip)
- weighted.example.com (some ip) -> 70 (some ip)
- weighted.example.com (some ip) -> 20 (some ip)
70% of traffic will be sent to the second resource.
A weight of 0 means don't sent traffic.
Use cases can be load balancing, testing new apps on a % of traffic etc
Latency-based
Routes requests from the user to the nearest resource
This is useful when latency is a priority
Failover routing
Failover routing is directly related to Health Checks (below).
If a resource is deemed unhealthy, then the failover routing will reroute the request to the healthy resource:
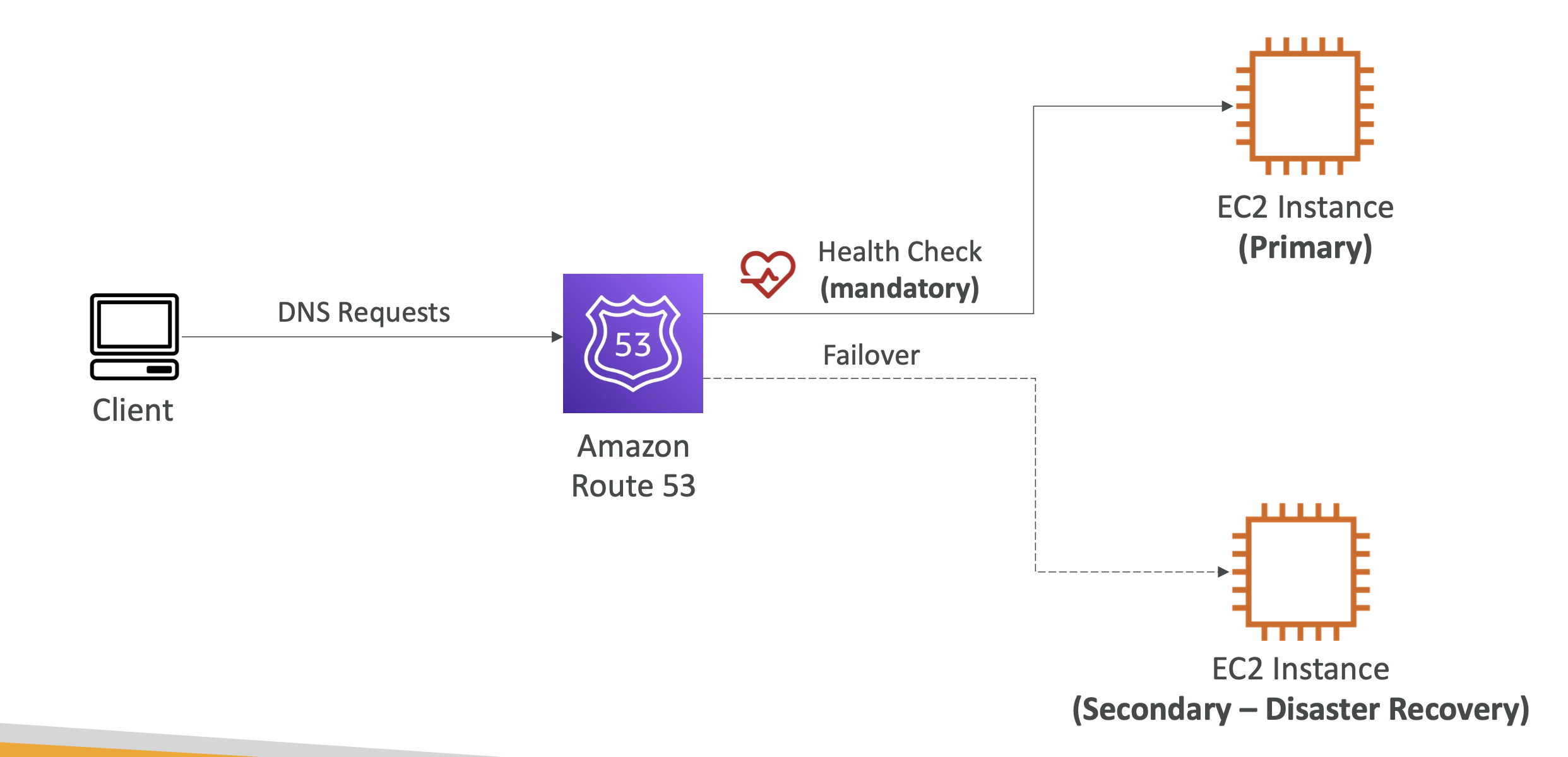
You define two records for the failover, if the primary records fails, it will failover to the second record.
Geolocation routing
This will route users based on Geolocation. It can be by continent, country, or even US state.
Can be associated with health checks.
Use cases: website localisation, load balancing
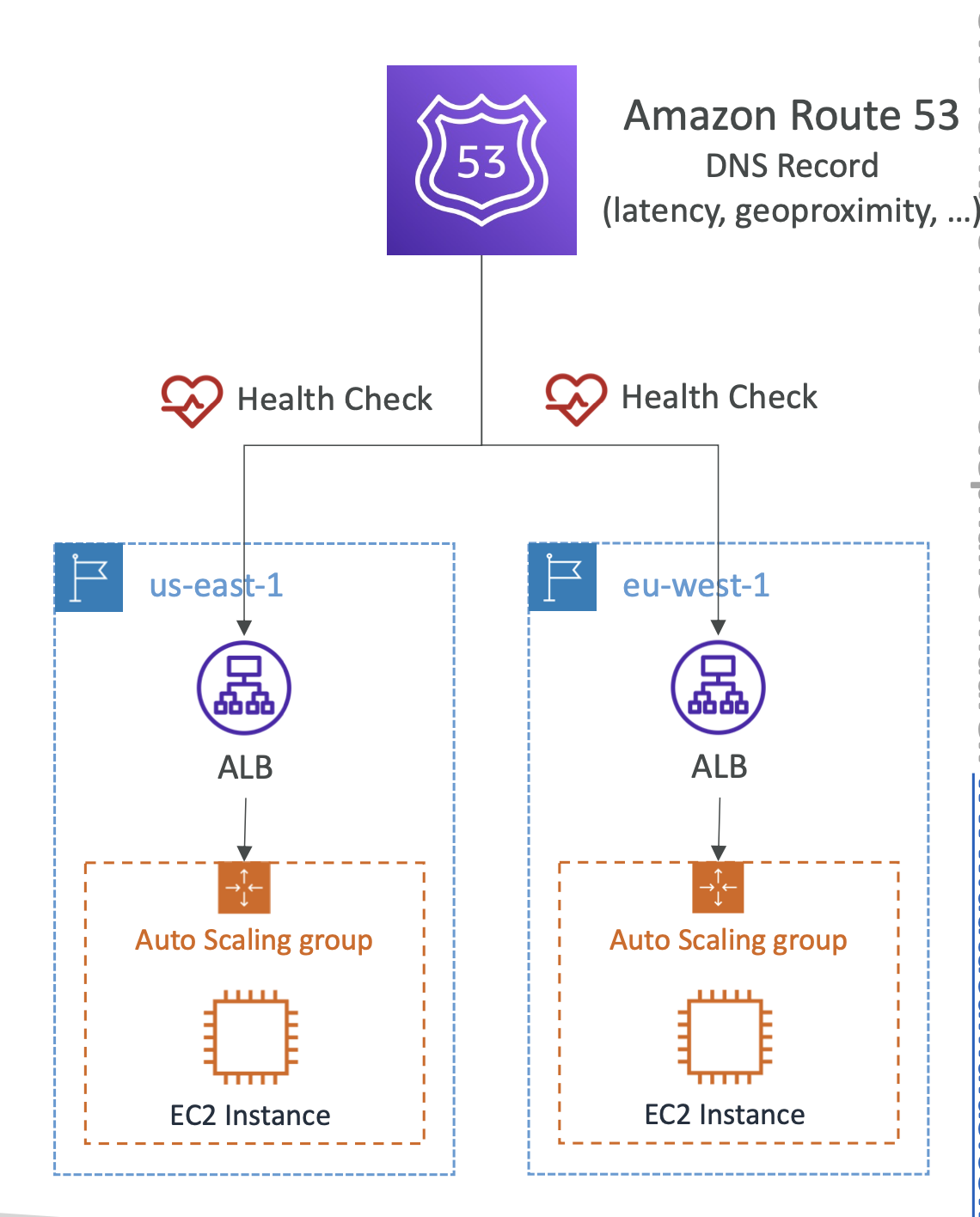
Health checks
Health checks check the status of our instances and whether they are running or down.
They are for public resources only. The health checkers come from outside our instances, so our resources need to be public facing to be evaluated by the health checkers.
There are three types:
- Health checks that monitor an endpoint (app, server etc)
- Health checks that monitor other health checks (Calcualted Health Checks)
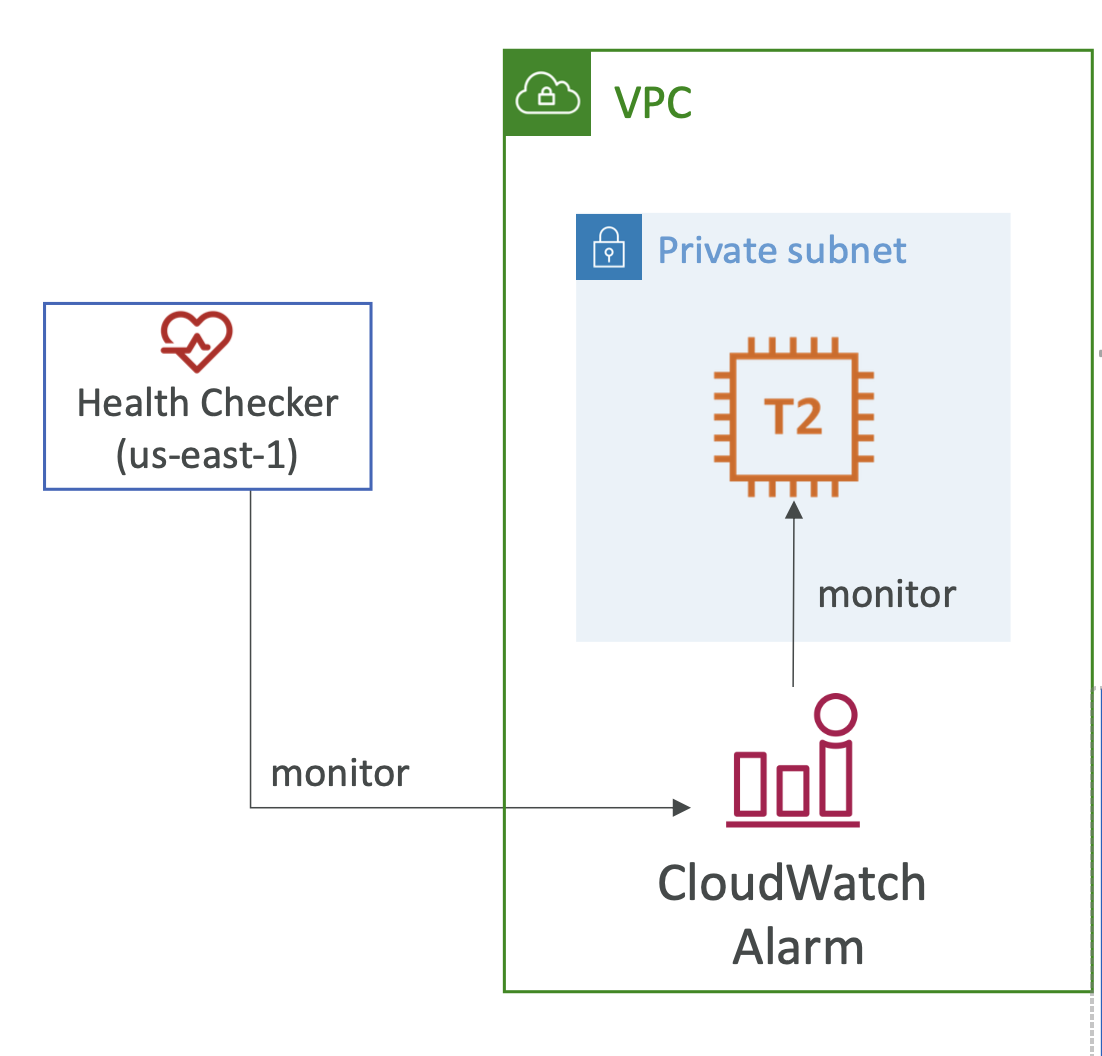
- Health checks that monitor CloudWatch Alarms (e.g DynamoDB, alarms on RDS)
Endpoint monitoring
- 15 global health checkers will monitor endpoint health.
- If endpoint responds with
2**or3**, then it's considered healthy, otherwise it's unhealthy:
Calculated Health Checks
- Combine multiple health checks into one
- Uses operators like AND, OR, NOT
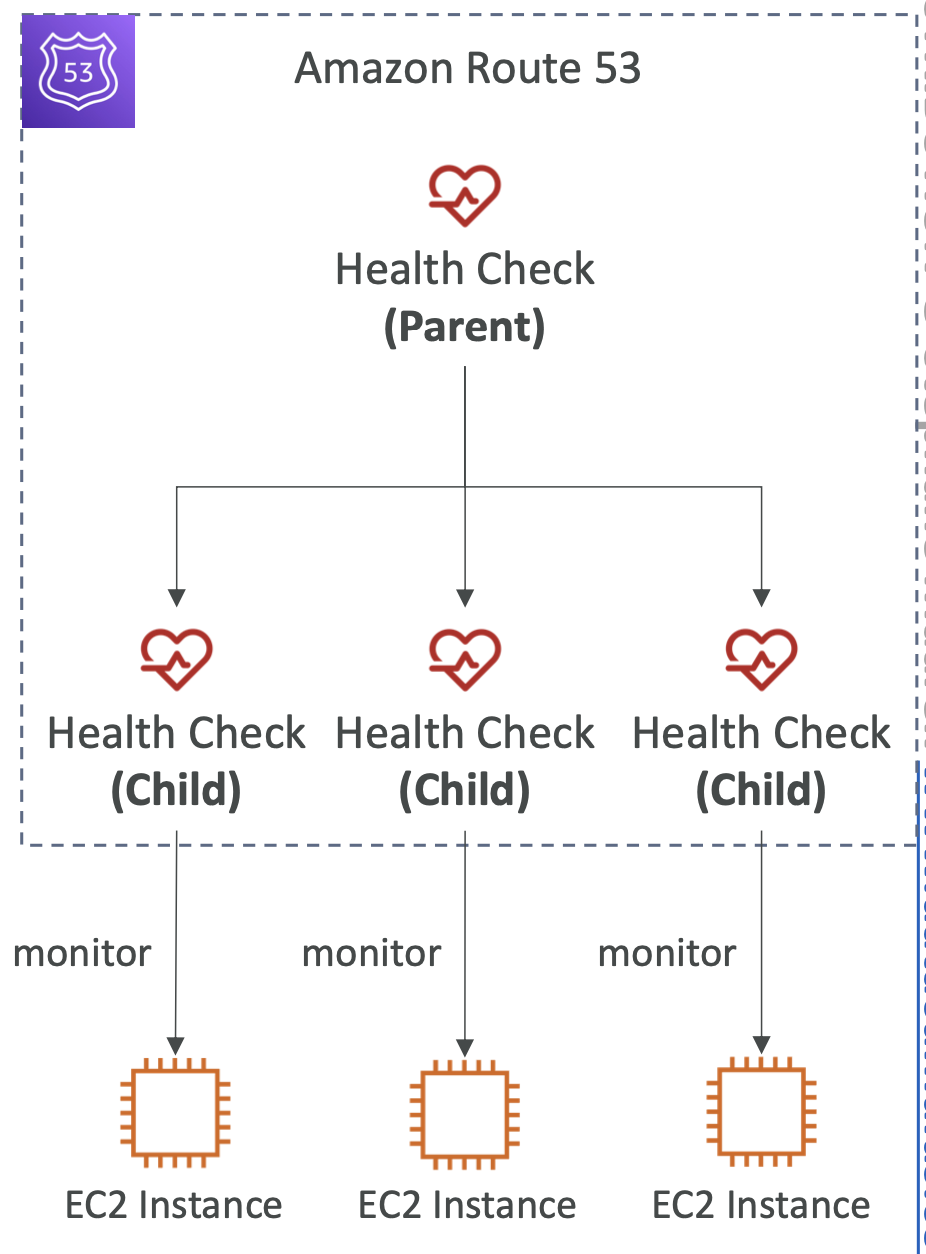
Private hosted zones
You can create a CloudWatch Metric and associated CloudWatch Alarm then create a Health Check that checks the alarm itself
Routing policies - failover
Associated a route with an instance, which has an attached health check.
If the health check fails then the request is routed to a second instance:
Routing policies - geolocation
This allows you to define an IP per country:
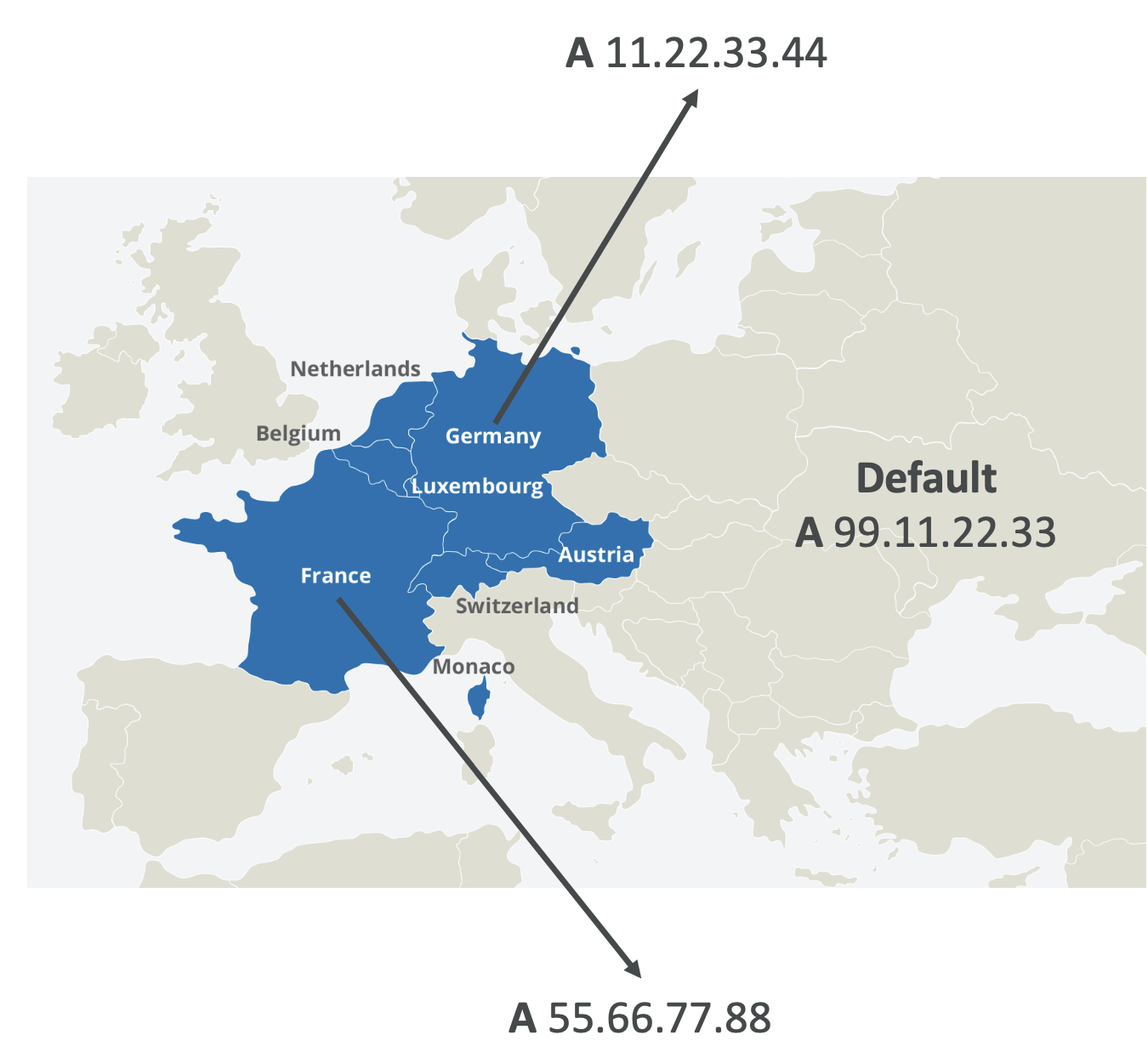
- Different from latency based
- Based on user location
- Can specify by continent, country, us state etc
Use cases can include: localisation, restrict content distribution, load balancing
Routing policies - geoproximity
This will automatically route traffic based on user location.
Locations can have a bias, which shifts more traffic to that resource and will gravitate user to that location:
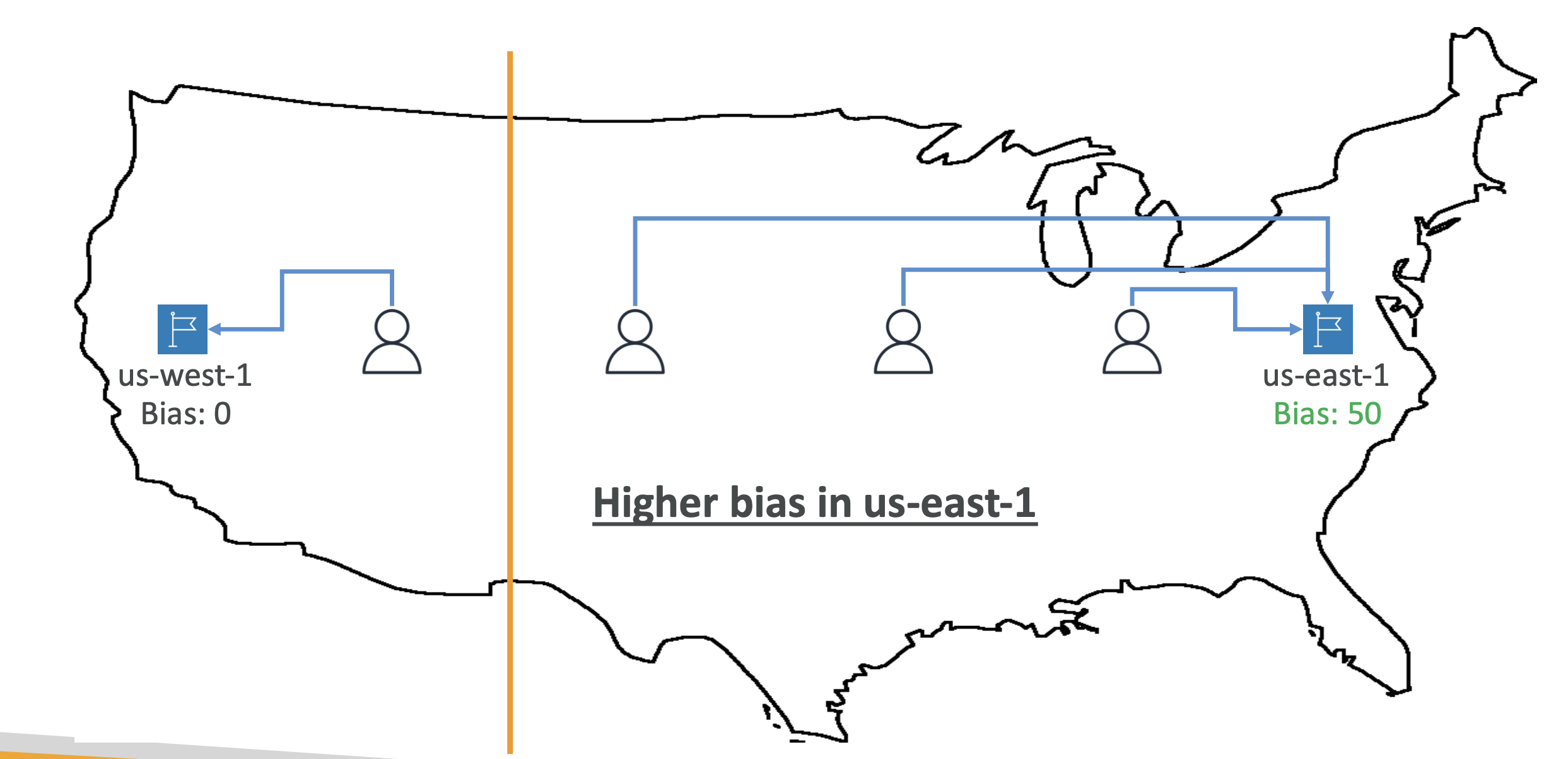
Routing policies - IP-based
Routing based on clien-IP's addresses using CIDR blocks
CIDR blocks are groups of ID addresses sharing the same network prefix. This allows us more control over addressing continuous blocks of IP addresses
If a user IP falls within the range defined by the CIDR blocks, they will be routed to the specified instance:
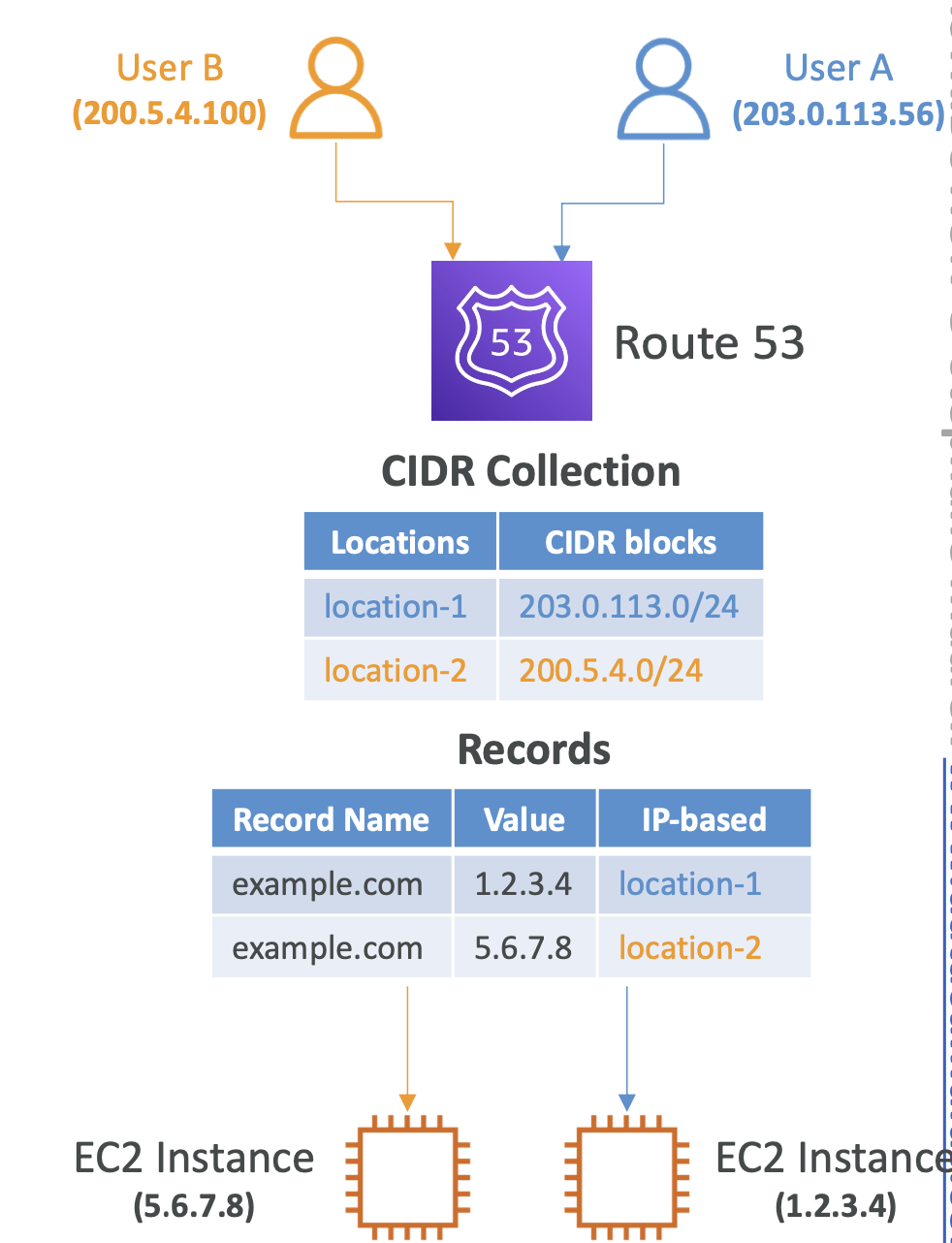
Routing policies - multi-value
This returns multiple record values and can be associated with health checks. When a request is made, all valued can be returned and the client can choose one.
As each record can be associated with a health check, it means that the client can choose a value that is up and running. For e.g if there are 3 records and only 2 are healthy, only 2 will be returned.

This is not a substitute for having an ELB
Domain registrar vs DNS service
You can use any domain name registrar, it doesn't have to be Amazon and you can use Amazon's Route 53 to manage DNS records.
For e.g buy a domain in GoDaddy and set GoDaddy's Nameservers to Route 53's name servers. Therefore when a request is made to GoDaddy, it will use Route 53's servers for routing.
Elastic Netowrk Interfaces (ENI)
https://aws.amazon.com/blogs/aws/new-elastic-network-interfaces-in-the-virtual-private-cloud/
ENIs are a virtual network card that give EC2 instances network access.
Each ENI can have:
- a private iPV4 (or more)
- one elastic IPv4
- one public IPv4
- security groups
- a MAC address
They are AZ bound and can be moved to other EC2 instances.
Network cards are a hardware component that allow computers to connect to networks ENIs are outside of the EC2 instance, although they affect them they just aren't shared by the instance
Each EC2 instance has one network interface.
Moving an ENI between instances allows for quick failover.
EC2 storage options
Storage options for EC2 instances
EBS Volume
Elastic Block Store - network drive. Allows for data persistence.
Can only be mounted to 1 instance at a time. It's bound to AZ. But you can attach more than one volume to an instance
Like a network USB stick. It's not a physical drive, it uses the network, so there is latency.
You can move it, but you've gotta snapshot the volume.
You can decide to terminate the EBS volume on instance termination
EBS Snapshot
- You can snapshot your volumes to act as a backup.
- Recommended to detach volume
- Can copy across AZs - allowing volume restoration in another AZ
- Copying to archive tier is much cheaper, but restoration is longer
- Snapshot deletions can be recovered from a recycle bin
- Fast Snapshot Restore (FSR) helps with latency on restoration
- Can also create other volumes from existing snapshots, which can be in a different AZ
EBS Volume Types
There are 6 types of EBS volume types
- GP2 / GP3 (SSD): perf/price balance
- io1 / io2 Block Express (SSD): High perf for low latency and high throughput
- st 1 (HDD): Low cost, frequent access, throughput intensive workloads
- sc 1 (HDD): Lowest cost for less frequent workloads
Characterised by SIZE | THROUGHPUT | IOPS (I/O Ops per sec)
Only GP2/GP3 and io1 / io2 can be used at boot volumes
General purpose SSD (gp2/gp3)
- Cost effective, low latency
- System boots
- 1GiB - 16 TiB
- Gp3: 2k - 16k IOPS & 125 MiB/s - 1k MiB/s
- Gp2: IOPS up to 16k. volume size and IOPS are linked
Provisioned IOPS volumes (io1/1o2)
- Critical business apps
- Apps that nmeed more than 16k IOPS
- Great for DB workloads
- io1: 4gb - 16tb max 64k IOPS
- io2: 4gb - 64gb - max 256k IOPS
HDD (st1/sc1)
- Can't be boot volumes
- 125gb - 16tb
- Throughpout optimised (st 1) - good for big data
- Infrequent access (low cost) - sc 1
Best resource: https://docs.aws.amazon.com/ebs/latest/userguide/ebs-volume-types.html
EBS multi attach
For io1/2 families you can attach same EBS volume to multiple EC2 instances in the same AZ.
This is good for high availability and concurrent writes.
Only good for one AZ and 16 EC2 instances at the same time
EBS Encryption
- Data encrypted at rest
- In flight encryption
- Snapshot encryption
- Uses KMs (AES-256).
Elastic file system (EFS)
Allows for a network file system that allows multiple AZ instances to connect to the EFS through a security group.

Use cases: content management, web serving, data sharing, Wordpress. Only Linux compatible (POSIX) system and scales automatically.
It has different perf modes:
- General purpose
- Throughput mode for Max I/O
And storage classes:
- standard
- infrequent access
- archive
Amazon Machine Image (AMI)
AMIs are customisations of an EC2 instance.
It's basically a snapshot of an instance that can be used to launch new, customised EC2 instances. This helps with faster boot times.
So far we have been launching using Amazon's own Linux AMIs. But we can:
- Create our own AMIs
- Used 3rd party vendor AMIs (can cost)
This allows for the following:
- Create an instance in one AZ
- Create AMI from that instance
- Launch a new instance from that AMI in another AZ
Hardware disk attached to EC2 instance, not a network drive, like EBS Volumes.
EC2 instance stores are higher performance storage for EC2 instance that are attached to the instance and aren't network drives
- Better I/O performenace
- EC2 instance termination will lose the disk (ephemeral)
- Not for long term storage, instead use EBS
- Backups are your responsibility
Solutions architecture
This section is meant to help us get into the mindset of a Solutions Architect working with real world problems.
We'll use a series of case studies to get into the SA "mindset".
Use case 1: Whatisthetime.com
Phase 1
Let's go from a simple static website to a full auto scaling one that can handle high levels of traffic
Our website simply tells the user what time it is using a T2 instance:
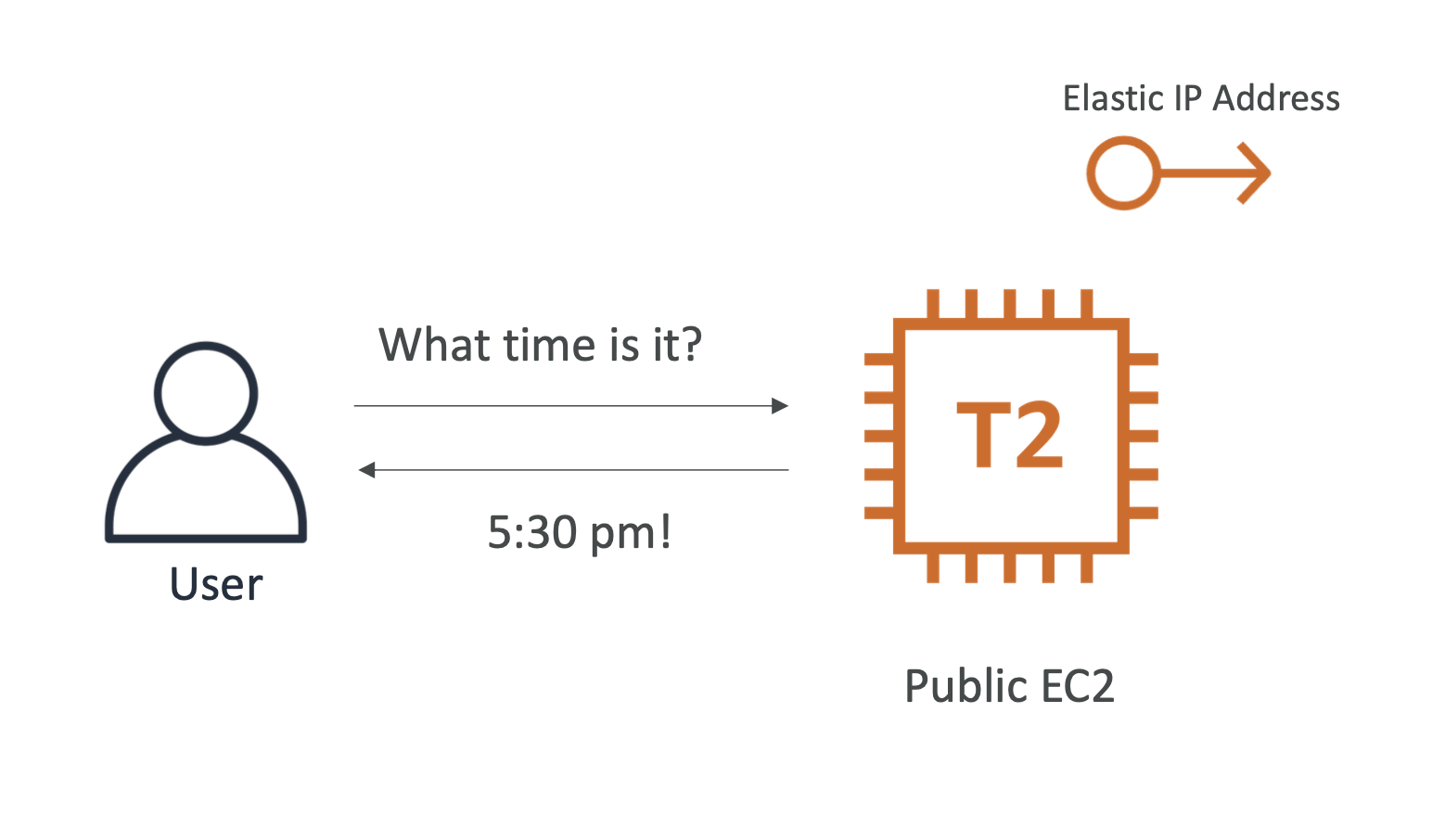
We want the instance to have a static IP, so we attach an Elastic IP address to it
Phase 2
Our app is getting more and more traffic and our T2 instance can't keep up. So we upgrade to an M5 instance, with the same public IP (vertical scaling).
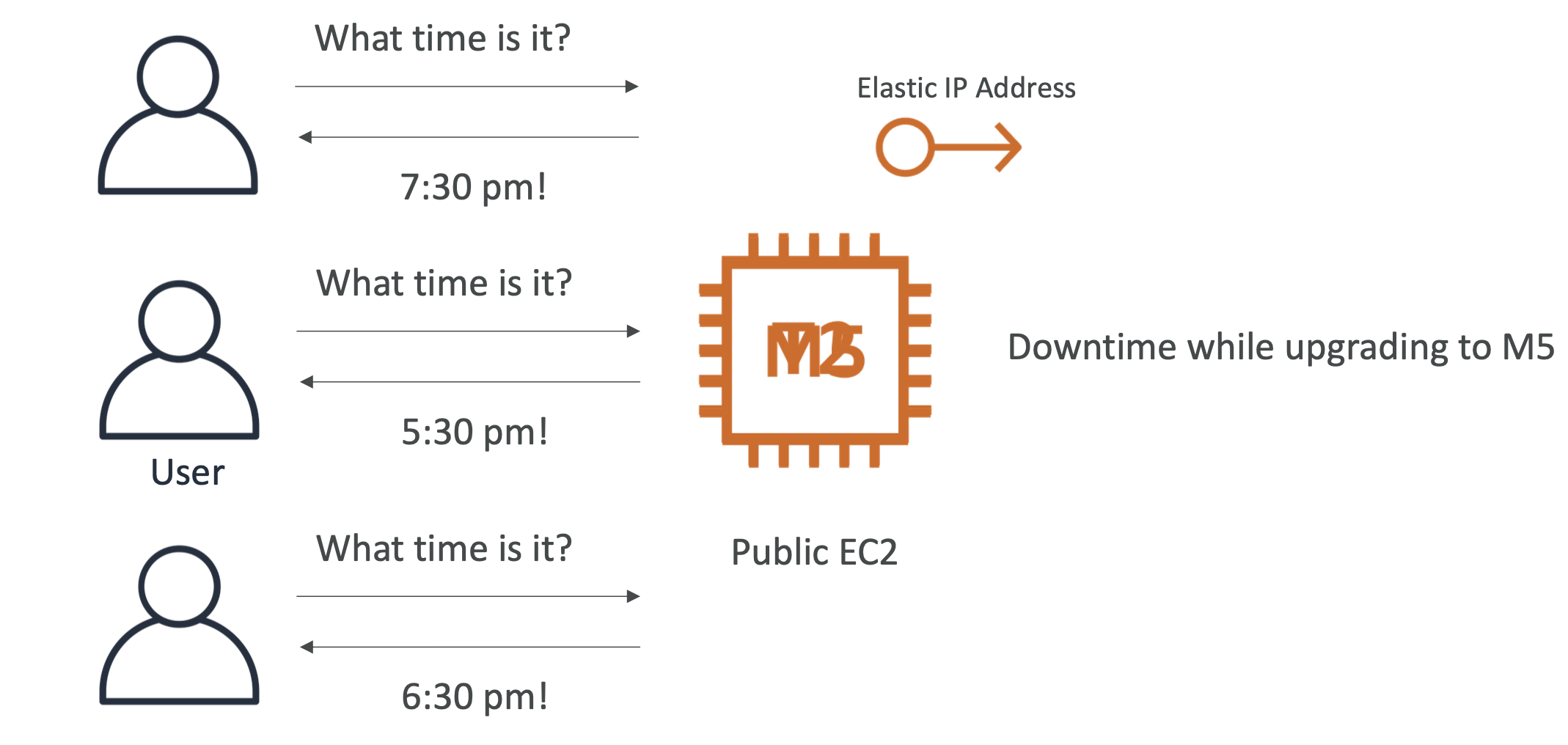
Because we had to upgrade, there was downtime, which isn't great! Our users aren't all that happy.
Phase 3
We are getting more and more traffic to our application and our single M5 instance can't handle it anymore. Instead of scaling vertically, this time we scale horizontally by adding more machines for our app:
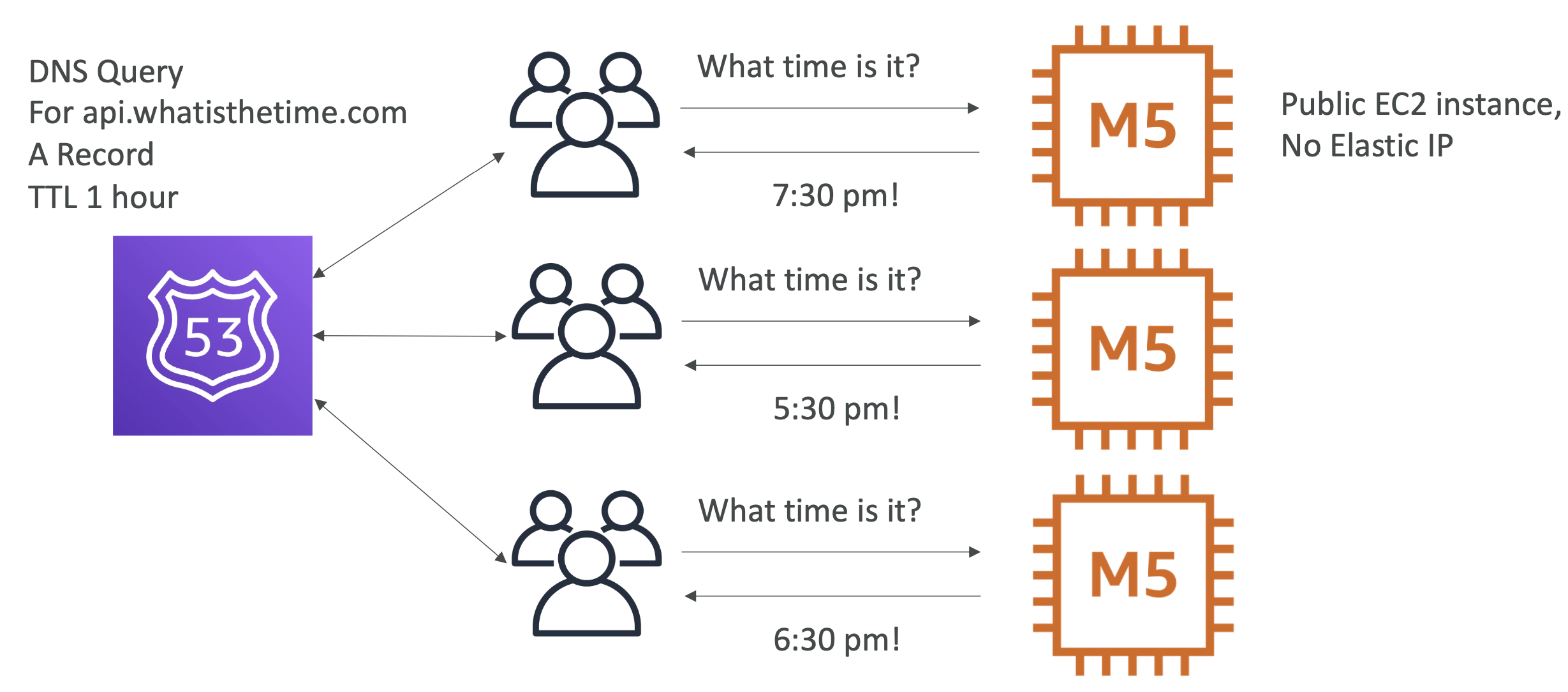
Each machine has a static (elastic IP), so we need to manage routing users to the specific instances we want them to go to.
User having to be aware of the IP is an issue here, it adds workload and is an inefficient way to route users, because it's manual
Phase 4
To overcome this static IP issue and having to route users ourselves, we will use Route 53 to handle this for us. This means that if our instance IP changes, we can just update our Route 53 A records and there will be no down time:
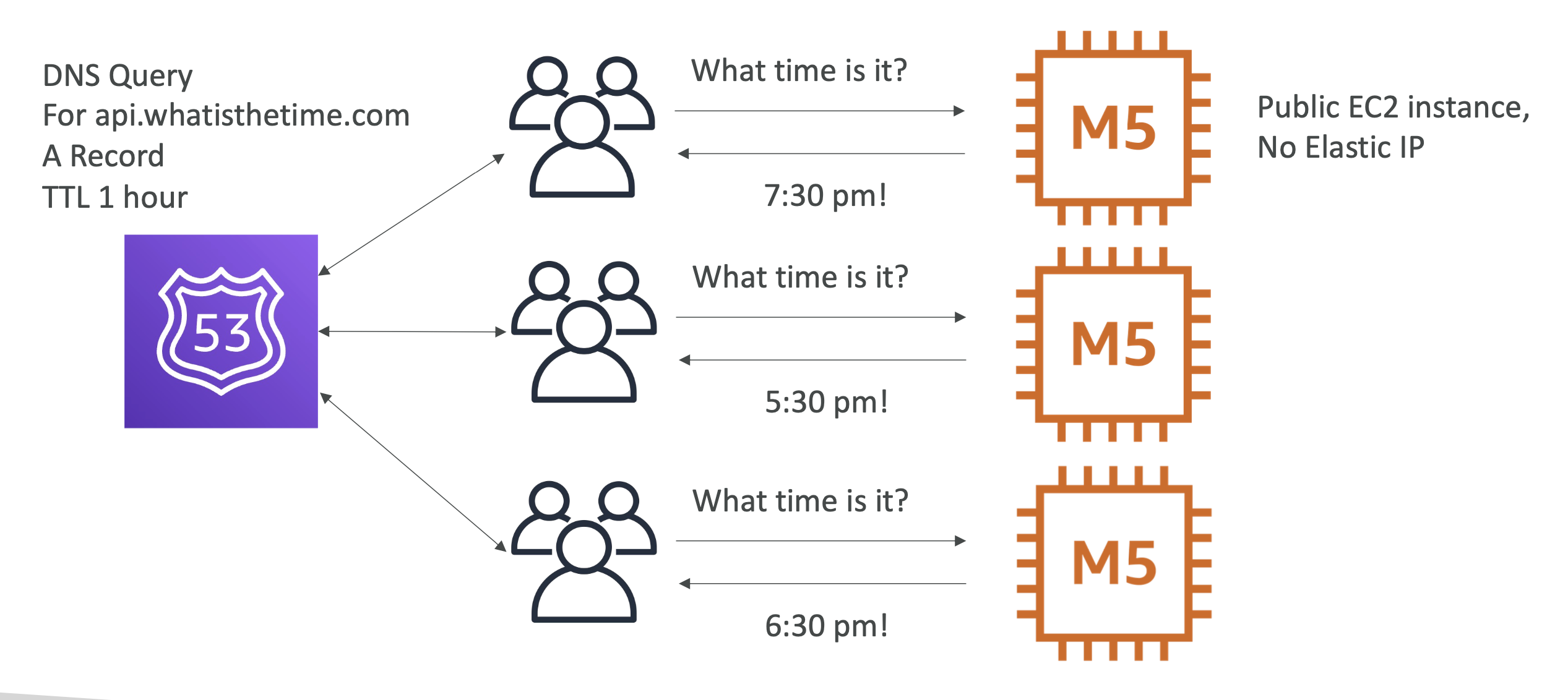
We remove one of our instance, which had an A record pointed to it with a TTL of 1 hour:
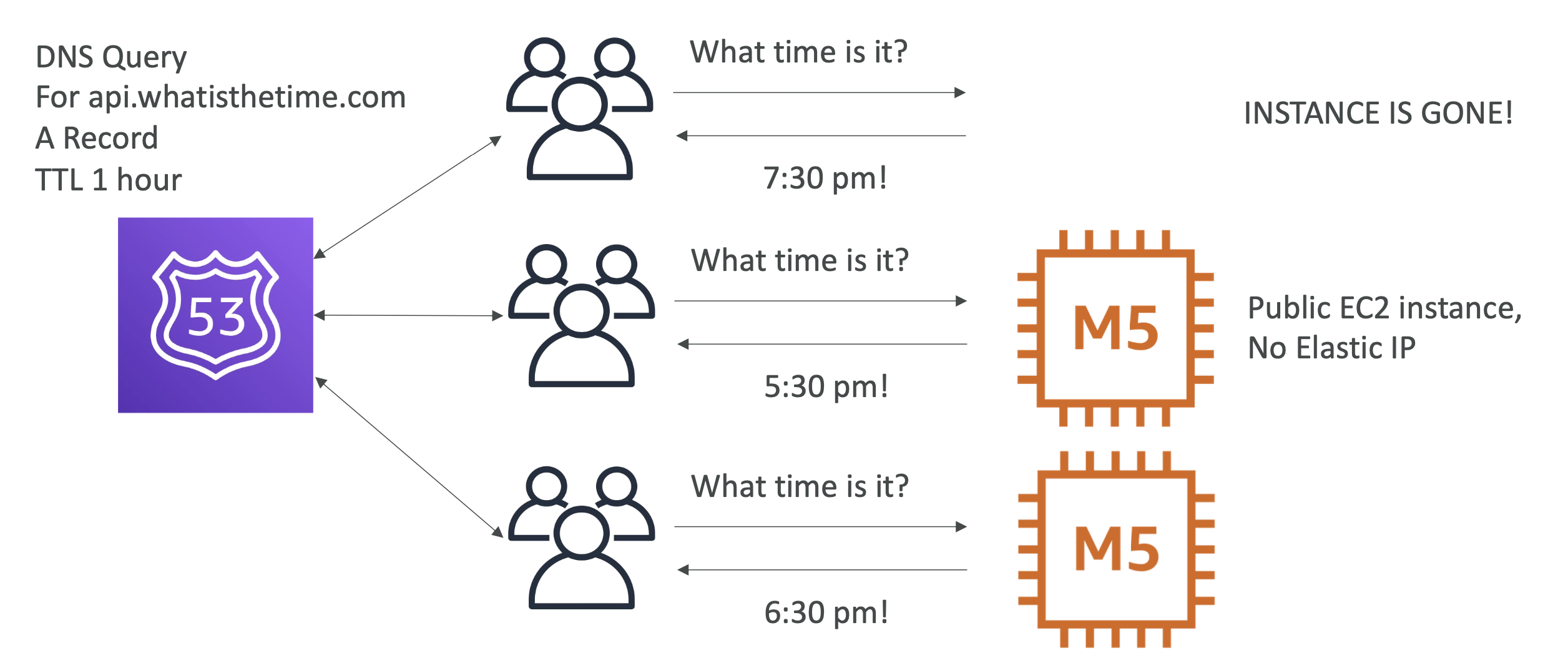
This meant that the users didn't see anything for one hour because the A record was still around for an hour.
Phase 5
Let's completely change our architecture. We don't want any downtime and we don't want to have to manage static IPs for each instance.
So we will use an ELB with health checks. This ELB will be public facing, and our M5 instances will be private. The ELB will point to our private instances. When a suer request is made to our API, it will route requests to our ALB, which will have a health check associated with it. If an instance is down we will route a request to a different instance.
However, because ELB IPs are dynamic and change overtime, we can't use an A record. Instead we use an alias record, which simply points to the ELB resource:
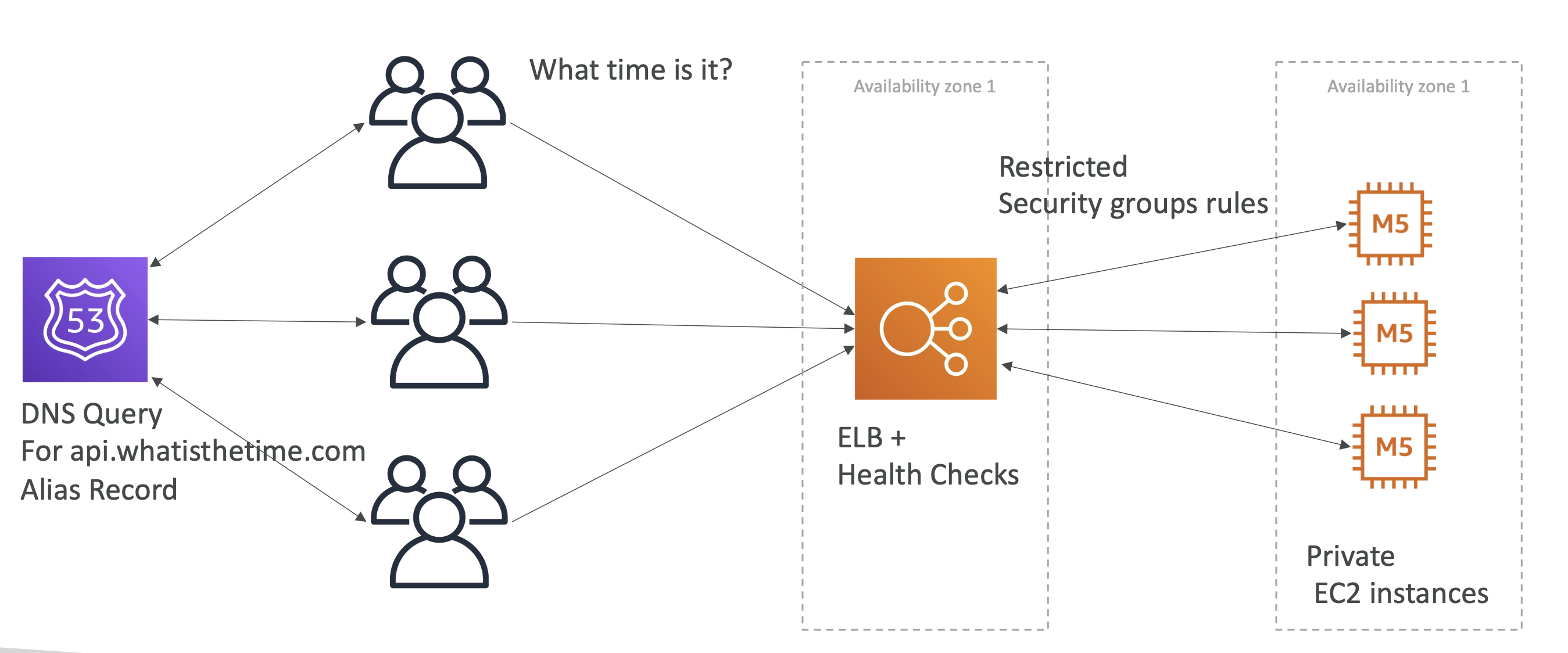
This allows us to add and remove machines over time without having to worry about downtime!
Phase 6
Adding and remove instances manually is pretty annoying to do.
So let's use an autoscaling group:
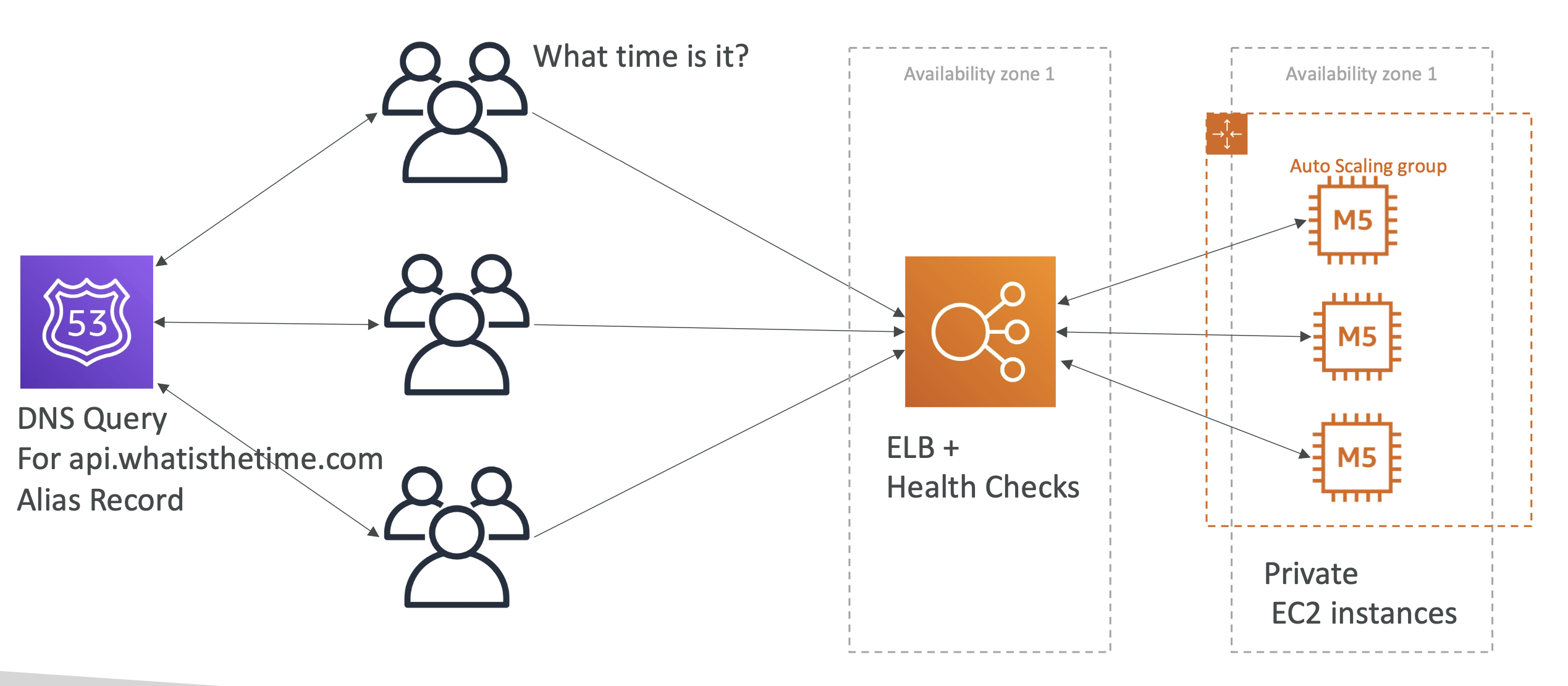
Phase 7
All our instances are in one region, though.
If there is a disaster in a region the whole app will go down!
So let's make it multiAZ:
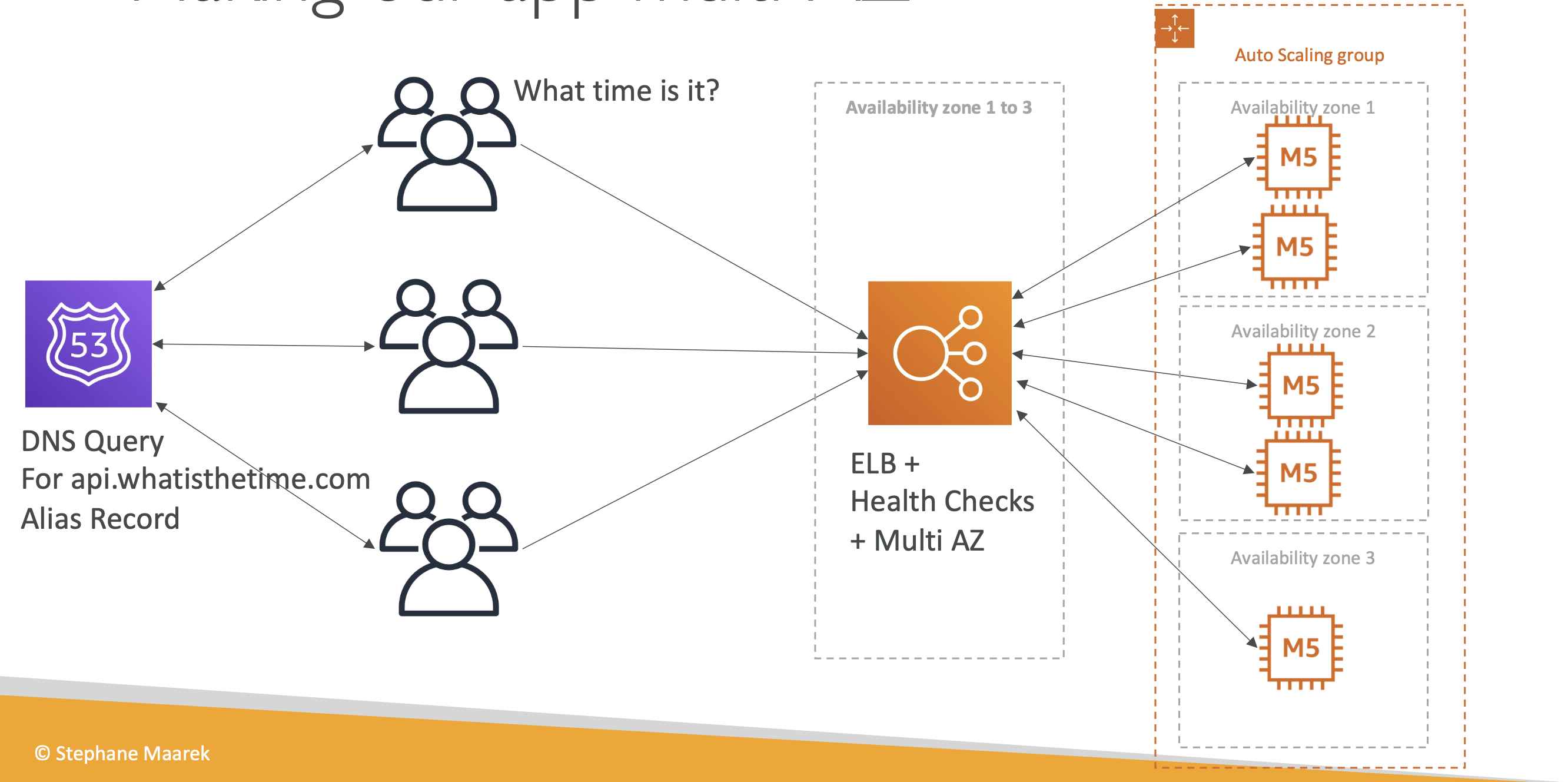
MyClothes.com
Stateful application, ecommerce use case with a "state" of shopping cart. Customers have details in a DB.
The problem
With our previous architecture, there is no state and consistency for the user. Our load balance will direct users to different instances each time.
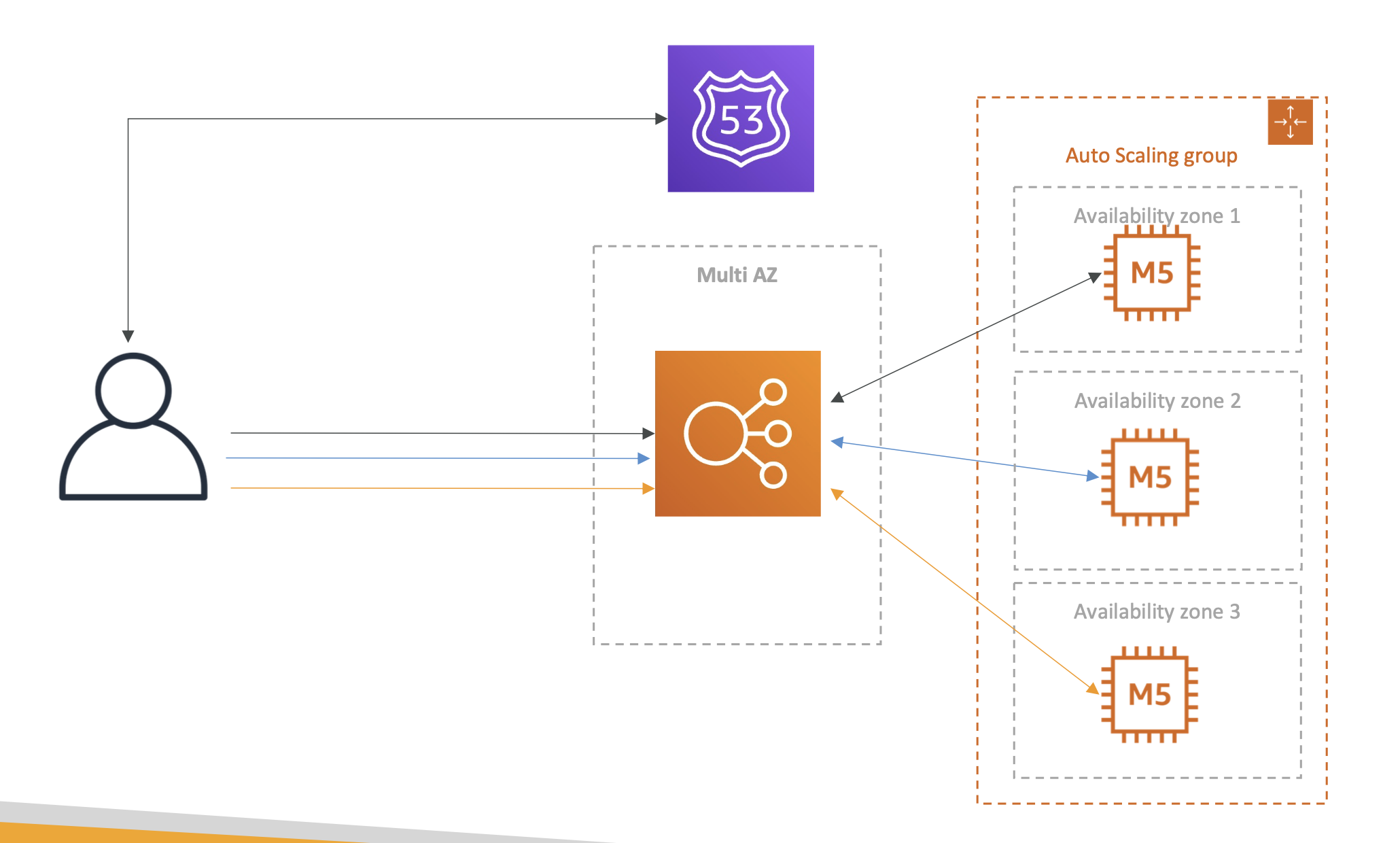
Meaning if a user adds something to carts and navigates away, they lose their shopping cart state.
Phase 1
To solve this, we can introduce ELB stickiness, which is an ELB feature that ensures the same users accesses the same instance with each request:
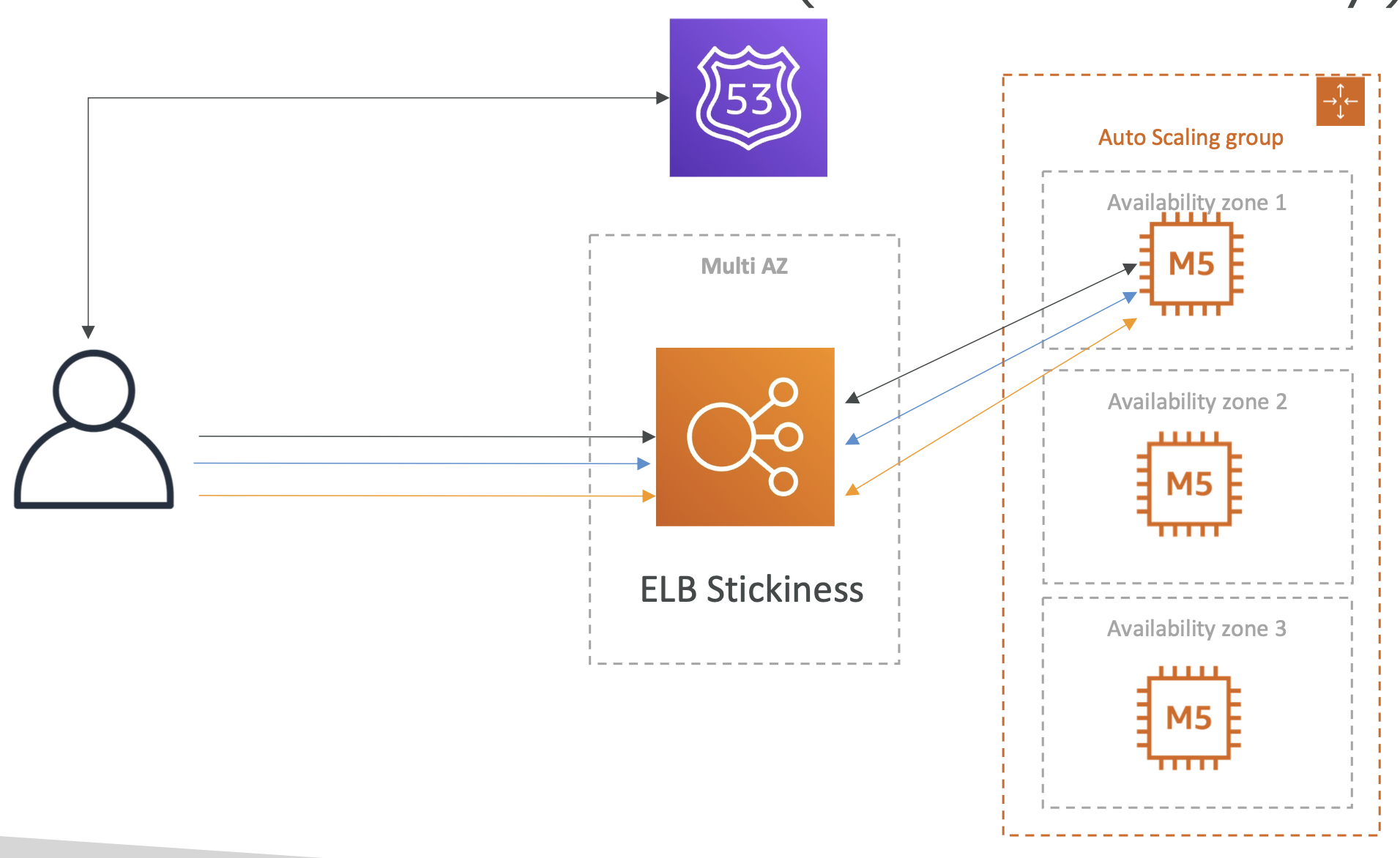
However, this introduces another problem, that if one of our instances goes down, the user will lose their stickiness and their cart will again be empited on refresh.
Phase 2
To solve this, we can use cookies. The user will have cookies that store the state of their session, such as what producte are in the shopping cart.
Regardless of which instance the user gets, their state will be passed back and forth between client and server.
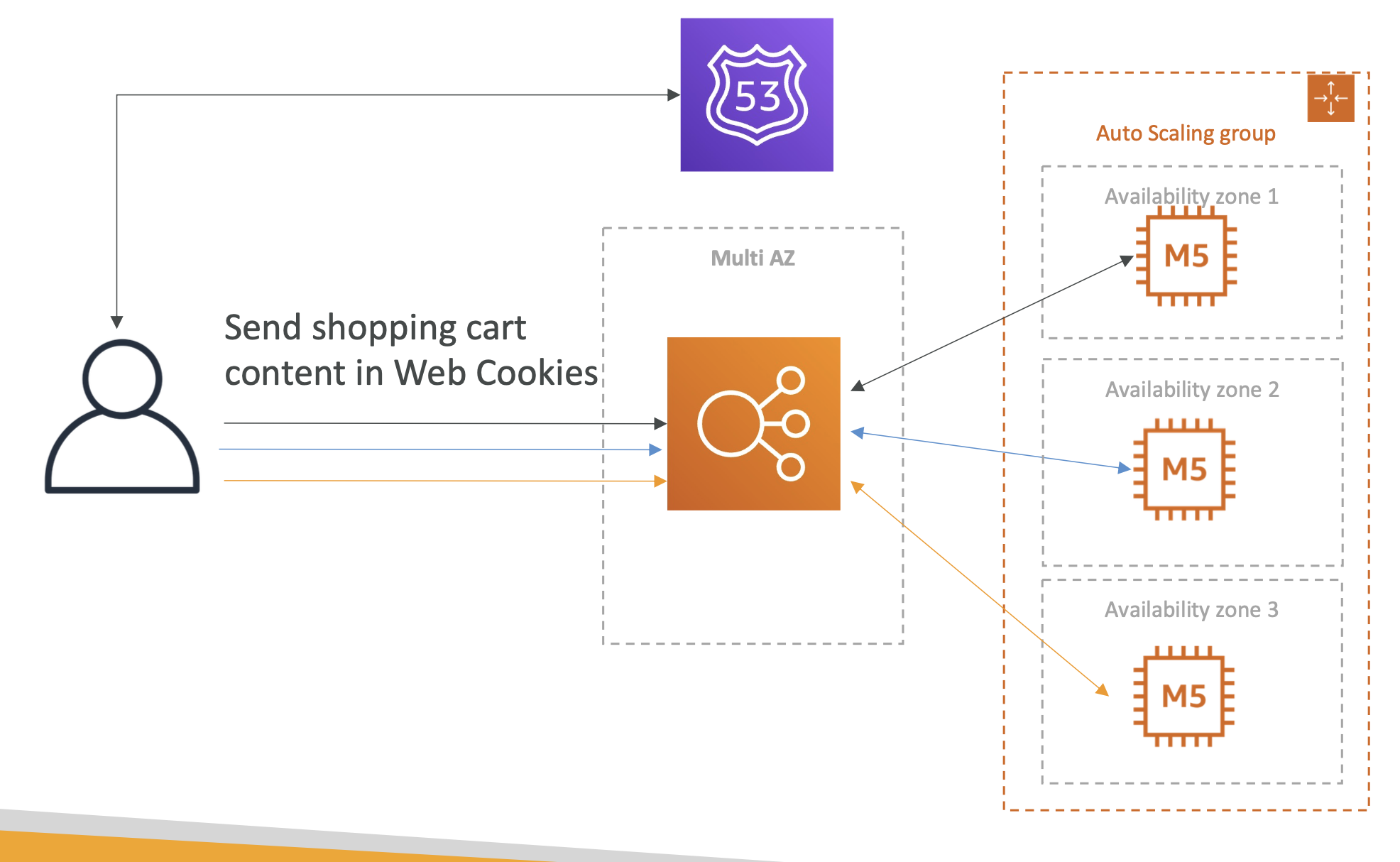
This allows us to achieve a stateless architecture, but there are some drawbacks:
- Security risk from cookies being altered
- Cookies must be less than 4kb
- Cookies must be validated
- HTTP requests are heavier
Phase 3
To overcome some of these drawbacks, instead of using cookies to store all user data, we just use a session_id and use ElastiCache or DynamoDB to store the session iinformation (such as cart info).
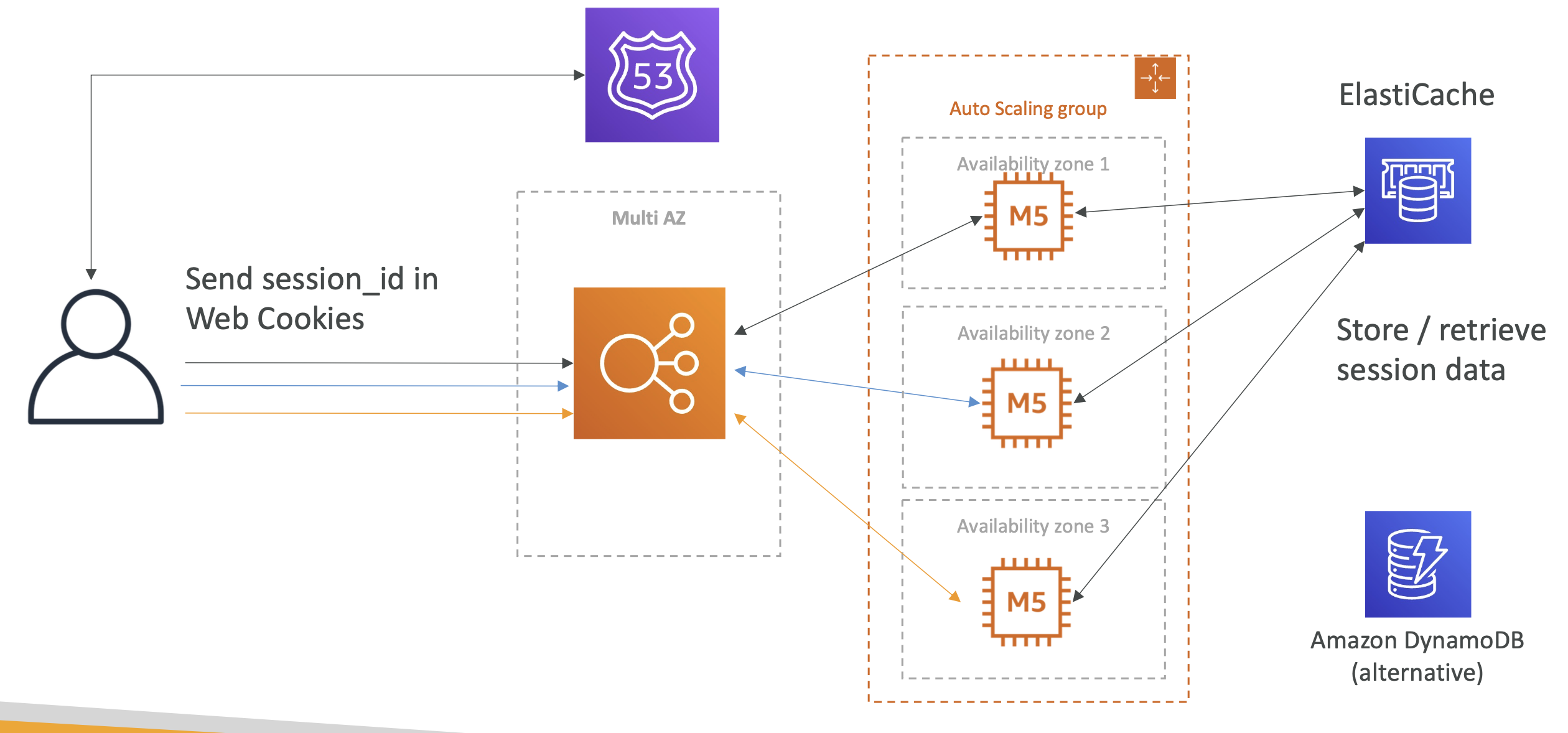
Regardless of what instance the user gets, the session_id will retrieve the right info from the DB.
Phase 4
What about long term user data and not session data?
We can use RDS for long term data such as address etc.
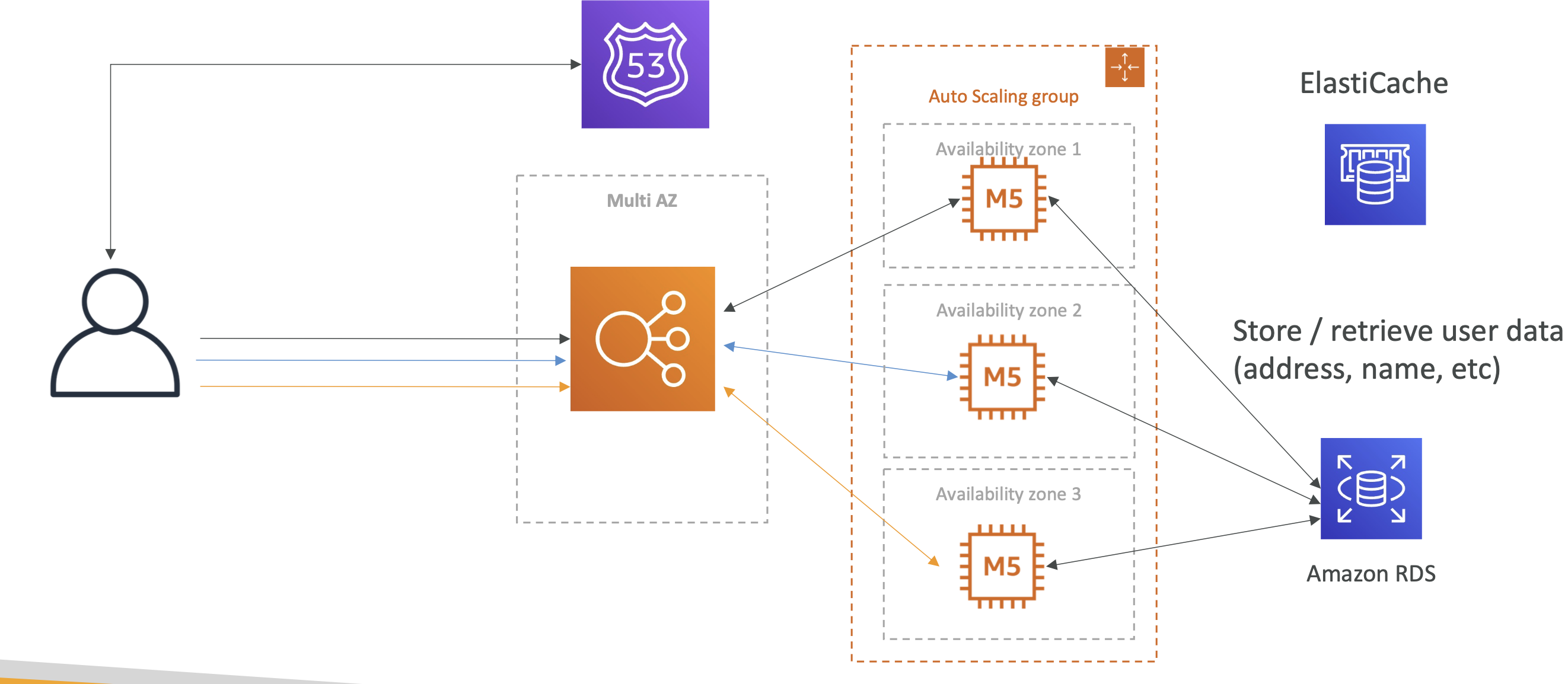
Phase 5
User are reading a lot of data from our website and it isn't scaling. To handle scaling we use RDS read replicas:
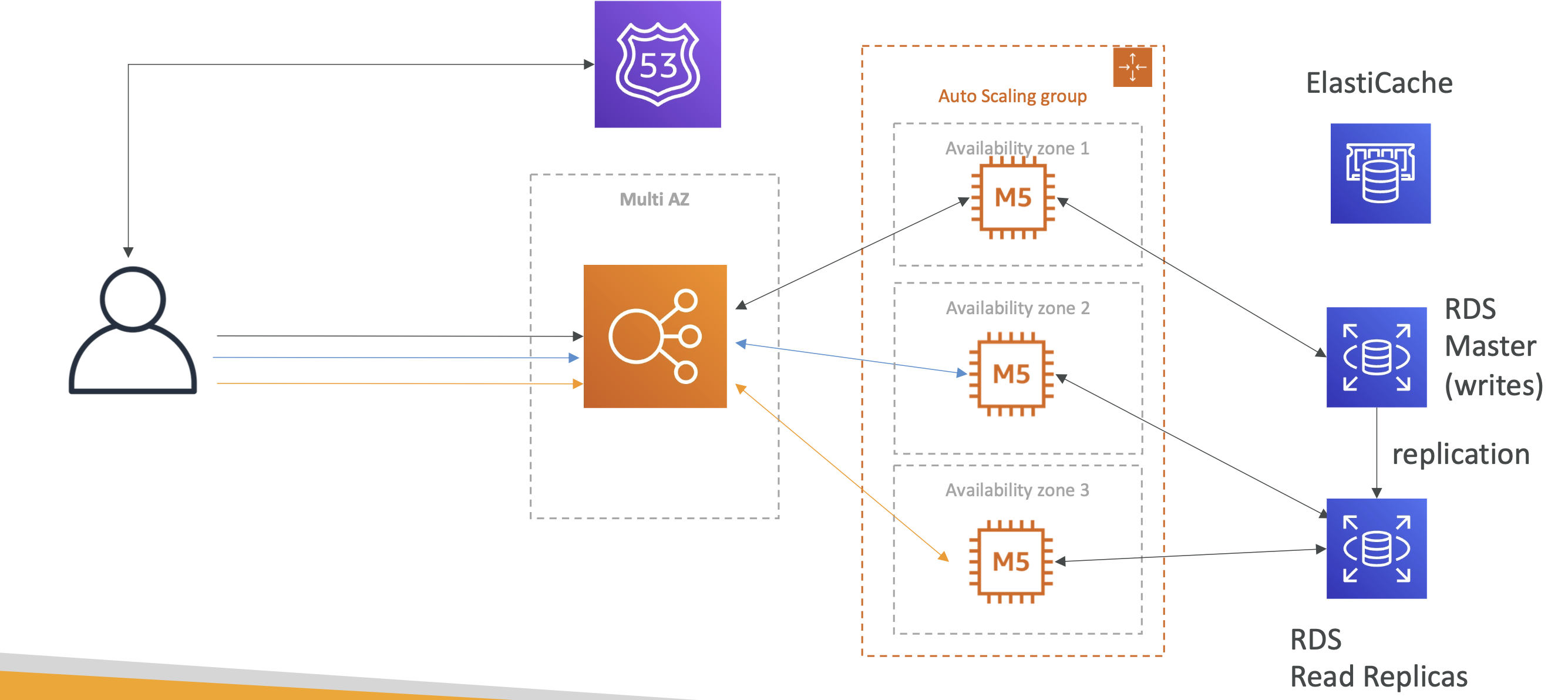
Phase 6
To survive disasters we can make our RDS multi az as well. To bolster security we can use security groups between the ELB and our auto scaling group of instances:
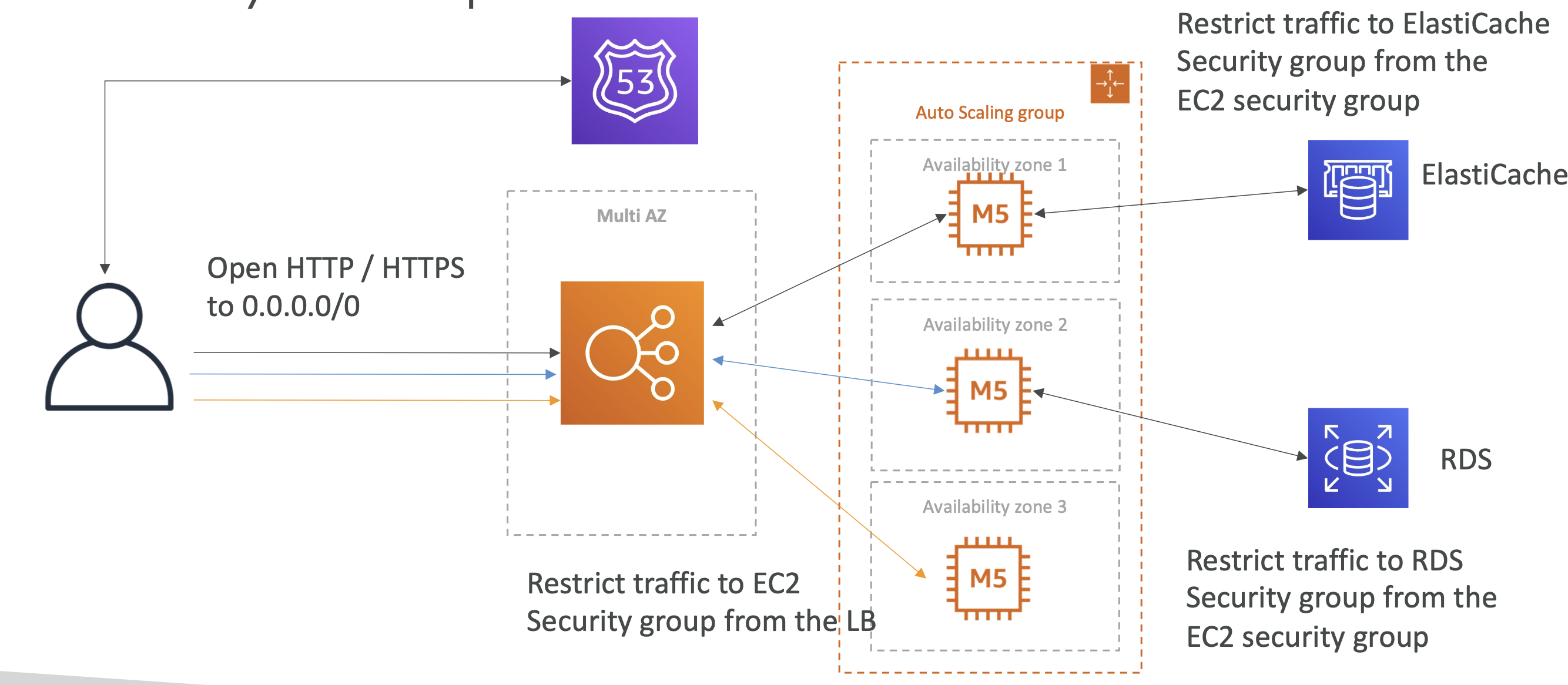
MyWordpress.com
We're trying to create a fully scalable Wordpress website.
We want website to access and correctly display picture uploads.
These images must be available globally.
We can use Amazon EBS for this (cloud block storage):
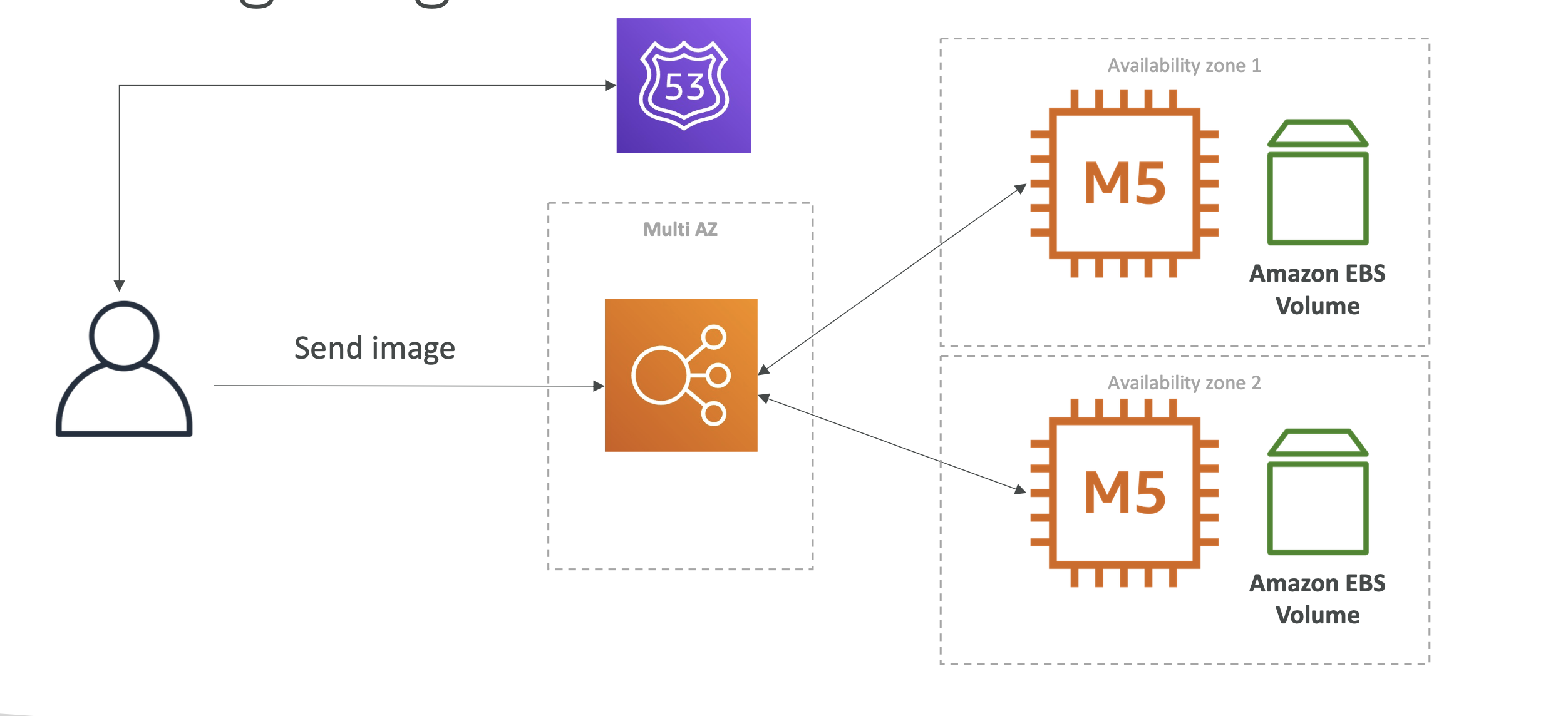
The problem with this approach is reads could hit different EBS volumes and get incorrect images. To solve this, we can switch to EFS:
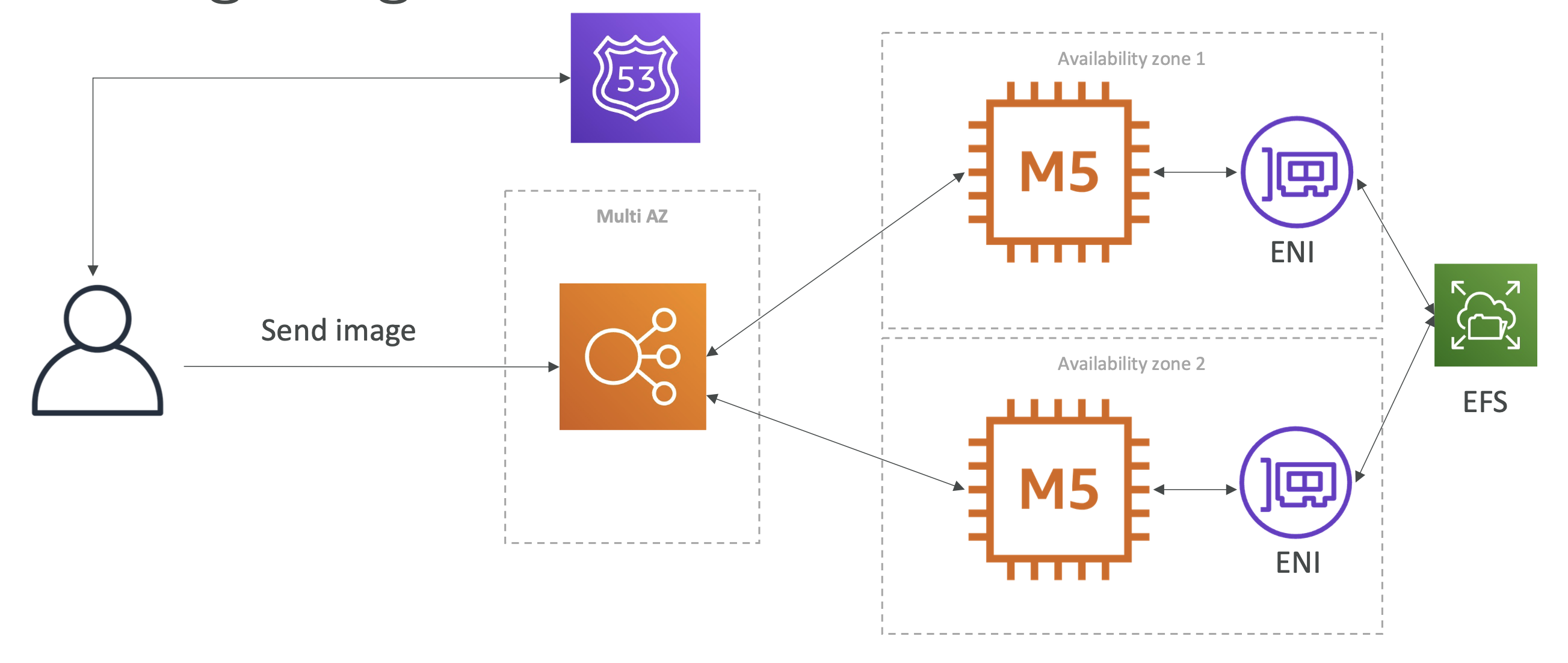
EFS is shared across all our instances, using ENIs and becomes our central image repo.
EFS is a common way to scale files across instances
Instantiating apps quickly
- EC2 Instances:
- Use a Golden AMI: Install your applications, OS dependencies etc.. beforehand and launch your EC2 instance from the Golden AMI
- Bootstrap using User Data: For dynamic configuration, use User Data scripts
- Hybrid: mix Golden AMI and User Data (Elastic Beanstalk)
- RDS Databases:
- Restore from a snapshot: the database will have schemas and data ready!
- EBS Volumes:
- Restore from a snapshot: the disk will already be formatted and have data!
Elastic Beanstalk
Elastic Beanstalk lets developers redeploy the same architecture over and over again.
As devs, we may repeat architectures and we don't want to have to have to reconfigure the same deployments each time.
Beanstalk is a way to manage deploying applications without us having to repeat ourselves. It's a managed service that will handle the deployments for ourselves.
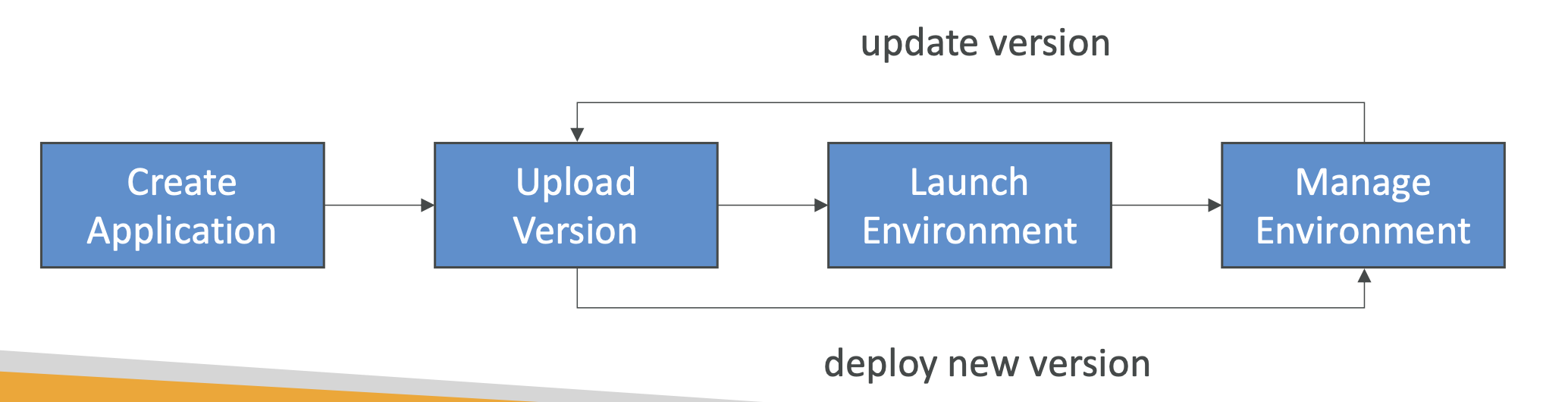
It consists of:
- Application: collection of Beanstalk components (environments, versions, configurations etc)
- Version: a new instance of your application code
- Environment: collection of AWS resources, with tiers and environments (dev, staging, prod)
Environments are either web server (HTTP requests) or worker environments (dealing with queues and messages). Web servers deal with client requests, workers deal with long running requests (such as handling tasks offloaded by the web server)
Amazon S3
Important section. S3 is the backbone of many Amazon services.
S3 is marketed as an "infinitely scaling" storage solution
Use cases
- Backup and storage
- Disaster discovery
- Archive
- Hybrid cloud storage
- App hosting
- Media hostiong
- Data lakes
- Static websites
- Software delivery
Buckets
- Files are stored in "buckets", which can be thought of as top level directories
- Bucket name must be globally unique
- Defined at the region level
- It's global but they're regional
- Naming convention:
- No uppercase
- 3-63 chars
- Not an ip
- Start w/ lowercase || number
Objects
Files are called "objects" in S3.
They have a key, which is the FULL path of the files.
The key is composed of a prefix + object name
There is no concept of directories, but the file names make you think otherwise
Object values are the content of the body. Max size is 5TB.
If the object is > 5gb then you have to use a multi part upload.
Objects have key > value pair metadata.
They also have tags and Version IDs.
S3 Security
User based
IAM Policies that define which users can make API calls to S3.
Resource based
- Bucket policies: bucket wide rules acros S3
- Object access control list: finer grain for specific objects
- Bucket access control list
an IAM principal can access an S3 object if IAM policy allows it and there's no deny rule
Encryption
Data can be encrypted using encryption keys.
Bucket policies
https://docs.aws.amazon.com/AmazonS3/latest/userguide/bucket-policies.html
This is the type of policy we will typically employ. The policies define who has access to a bucket. To see a list of policy examples go here.
You can also use a policy generator.
They are JSON policies:

The resource directive defines which buckets the policy applies to. The action directive are a set of API methods we can allow/deny, for e.g GetObject, meaning we allow anyone to retrieve objects in a bucket.
Typical uses for bucket policies:
- Allowing public access to a bucket
- Force objects to be encrypted at upload
- Allow account access within S3
Block public access
You can also block access at the bucket level within S3. This is an additional security measure from S3.
Example policy
Here is a policy we have generated using the policy generator that allows public access to our S3 bucket:
{
"Id": "Policy1746257646198",
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1746257644933",
"Action": ["s3:GetObject"],
"Effect": "Allow",
"Resource": "arn:aws:s3:::vim-demo-s3-v1.1/*",
"Principal": "*"
}
]
}
S3 static website hosting
S3 can also be used for static website hosting!
The URL can change depending on the region, either with a dot or a dash after the region:

Versioning
Versioning in S3 allows you to create versions of S3 objects. It is enabled at the bucket level.
If you enable versioining, each object will contain a version. Uploading an object will assign an key to it and uploading an object with a key will override the defined object.
It is useful to:
- Protected against unintended deletes
- Roll back to previous versions
Replication
You can replicate buckets two ways:
- CRR: Cross region replication
- SRR: same region replication
To enable this you must:
- Enable versioning in both source and dest buckets
- Give propoer IAM permissions to S3
Some caveats:
- Only new objects are replicated
- Existing objects can be replicate using batch replication
- Only delete markers are replicated
- Chaining isn't possible, e.g replicate from bucket 1 > 2 > 3
A delete marker in Amazon S3 is a placeholder (or marker) for a versioned object that was specified in a simple DELETE request. A simple DELETE request is a request that doesn't specify a version ID. Because the object is in a versioning-enabled bucket, the object is not deleted. But the delete marker makes Amazon S3 behave as if the object is delete
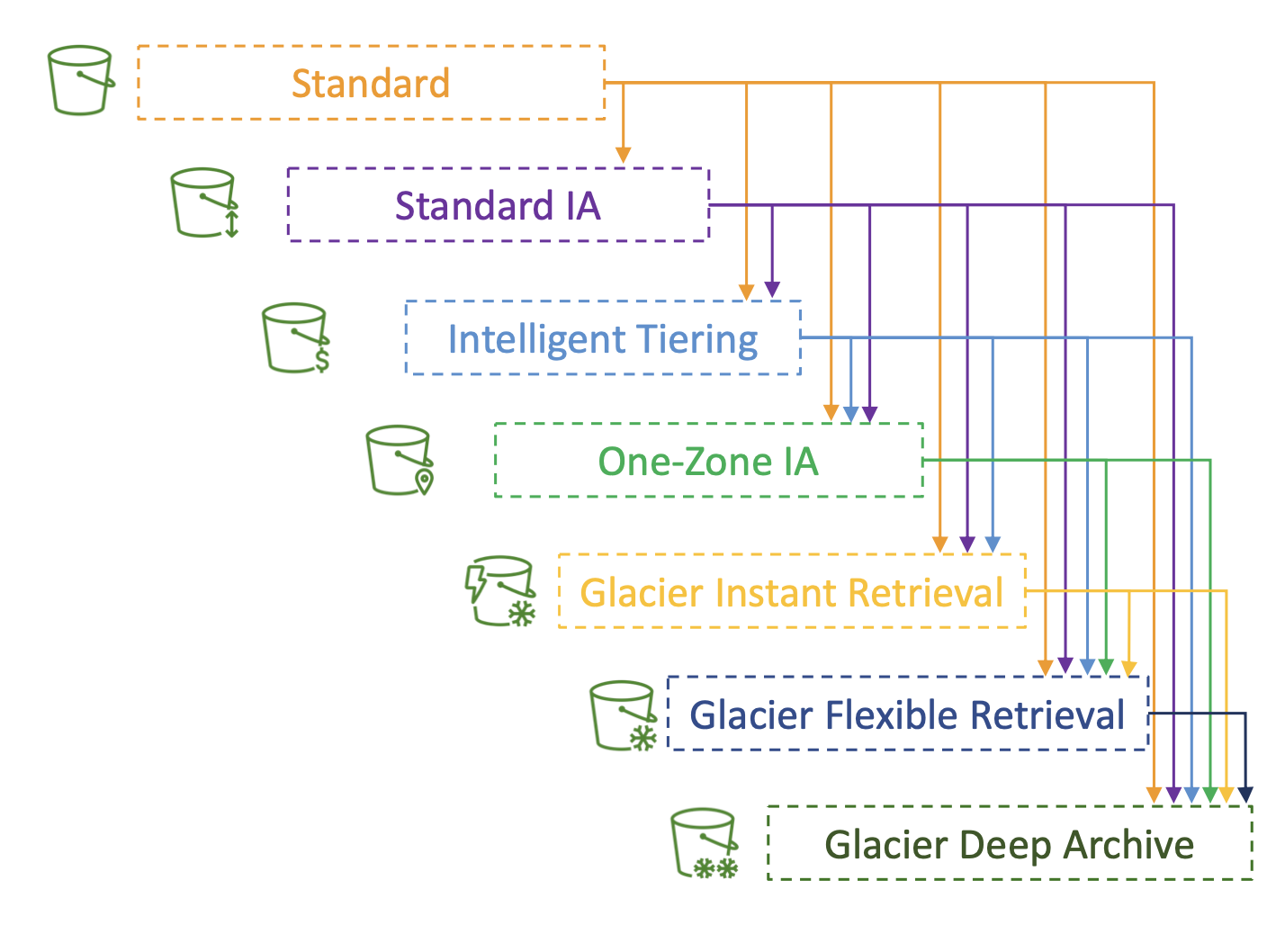
Storage classes
Concepts:
- Durability: how often you would lose items
- Availability: how ready the S3 service is
Refer to the slides for the details on this or this documentation
Advanced S3
Moving between classes
You can transition between Storage Classes in S3.
We can do this manually, but also automatically using lifecycle rules.
They can consists of two action types
- "Transition Actions": transition objects to another class (e.g move to Glacier for archiving after 6 months)
- "Expiration actions": delete stale files after 365 days.
They can target object prefixes and tags.
Lifecycle analytics
To help create lifecycle rules, S3 provided analytics (a .CVS export) to help you decide when to transition objects.
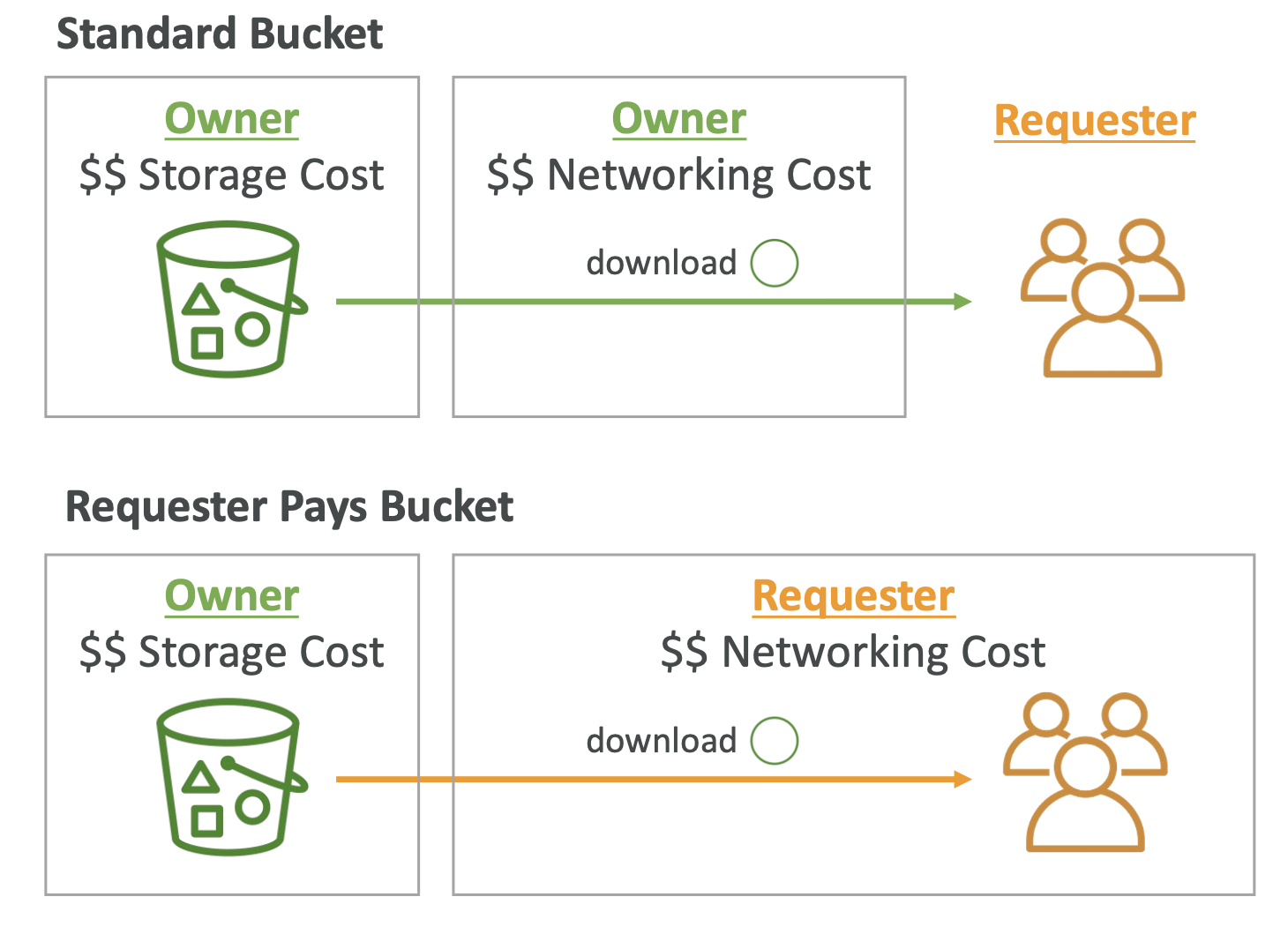
Requester pays
A requester pays bucket means that the requester will pay for the requests for the objects.
Typically, the bucket owner will pay for storage costs + network request, but this model means a requester will pay for the network request portion.
For this to work, the requester must be AWS authenticated:
Event notifications
Event notifiations let you respond to S3 events and do something.
Some example events could be:
- objectCreated
- objectRemoved
- objectRestored etx
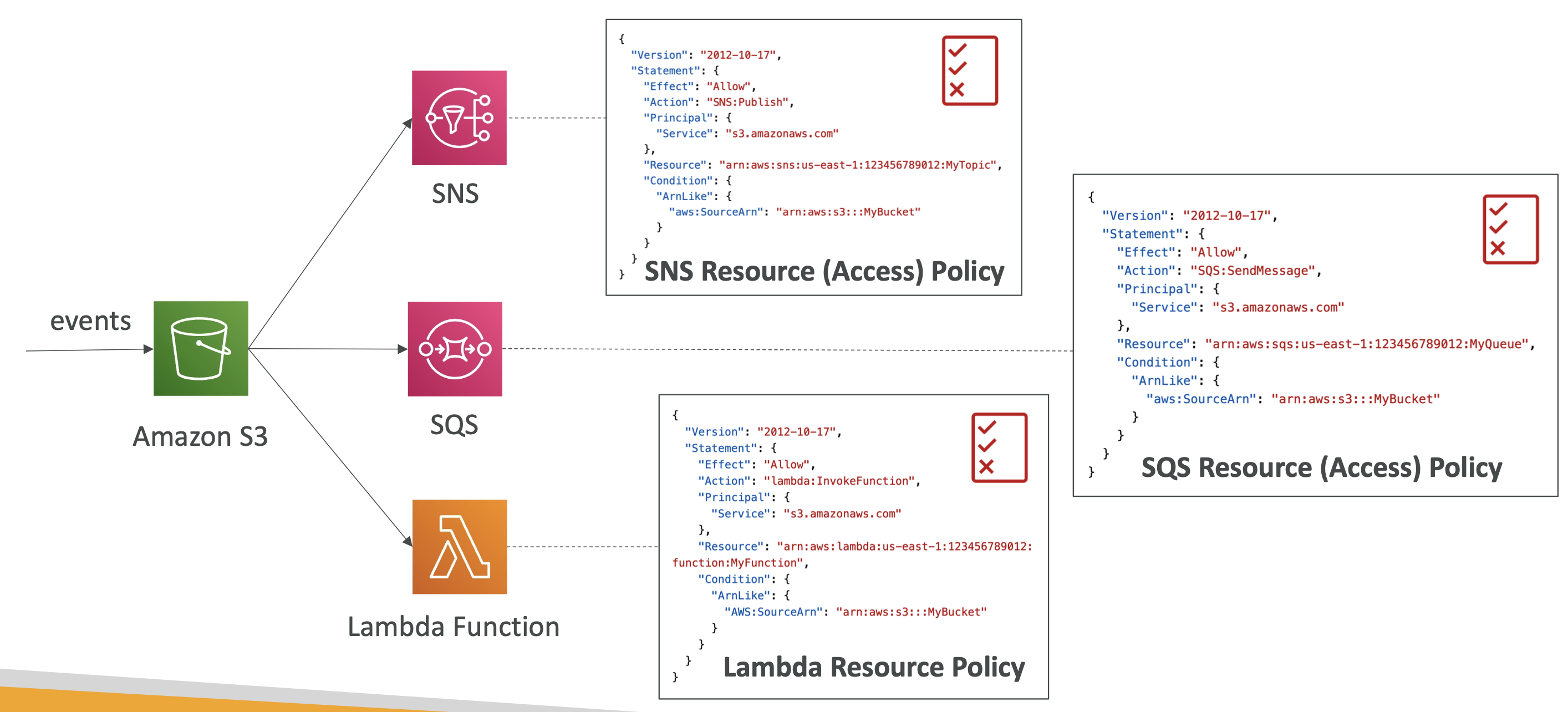
You can then take a follow on action:
- Run a Lambda function
- Send to SNS
- Send to SQS
Events can take a minute of longer
The ability to send data between S3 and Lambda, for example, is controlled by resouce access policies:
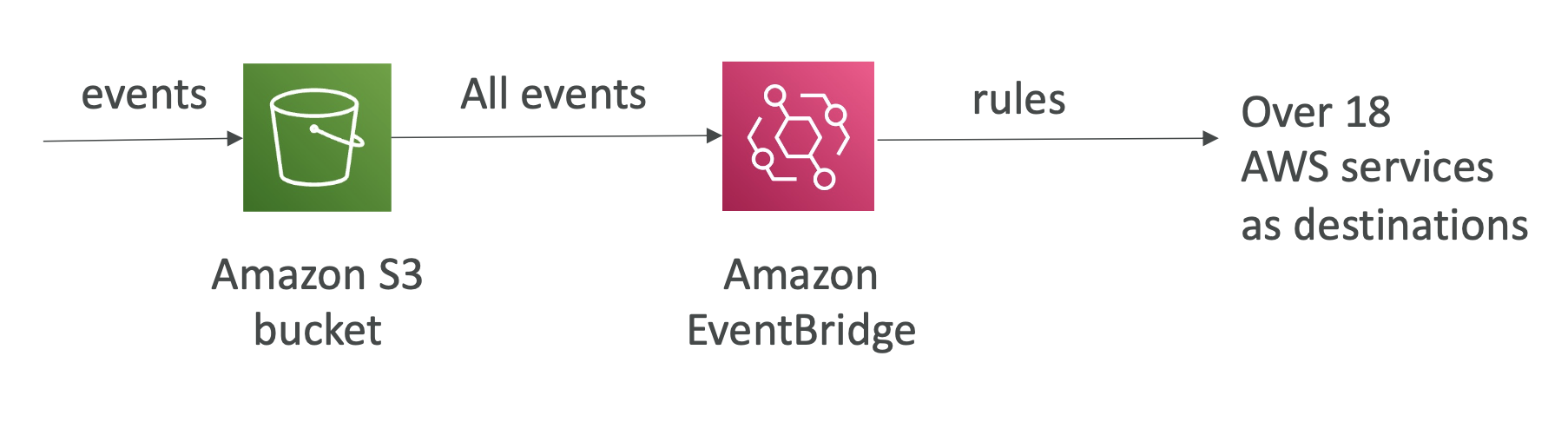
Event bridge
You can consolidate the event sendings through Amazon EventBridge
S3 - base performance
- S3 automatically scaled to high request rates, with a latency of 100-200ms
- 3.5k write operations and 5.5k GET operations per prefix per bucket (a prefix is the middle portion of a path: /bucket/folder1/sub1/file -> "/folder1/sub1/"
- Spreading operations across 4 prefixes you can get 22,000 GET operations per second
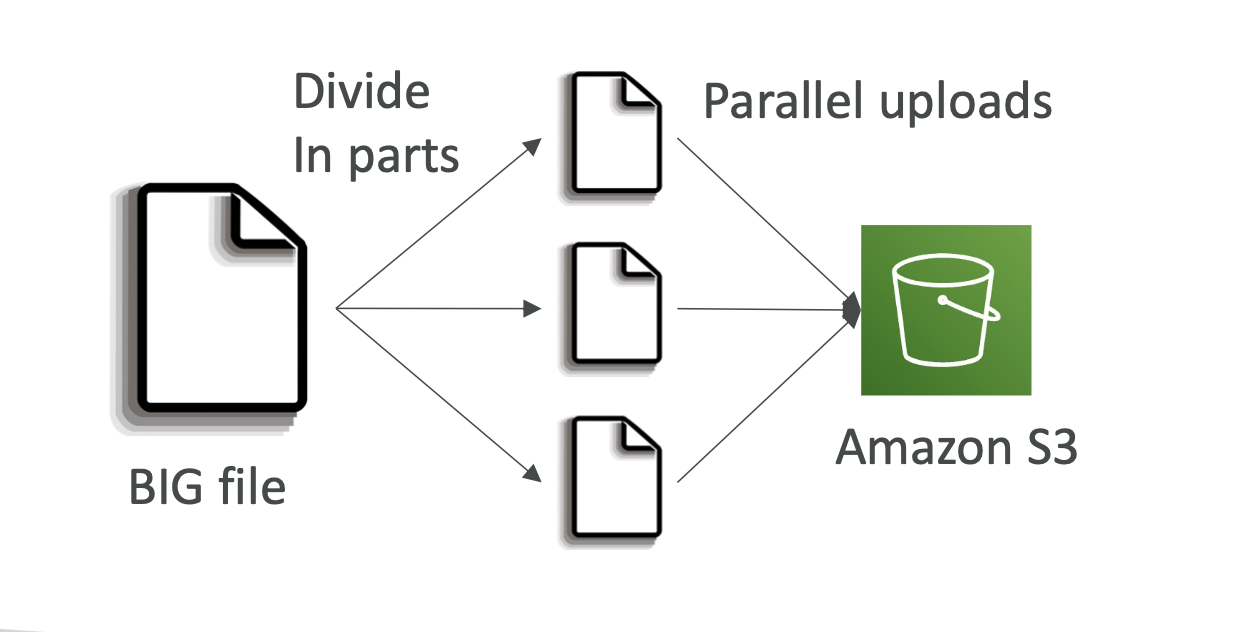
Optimising performance
- For files over 100mb (required over 5gb) use multi part upload, which parallelises uploads:
- S3 transfer acceleration: uses edge locations. It uses private networks to accelerate uploads
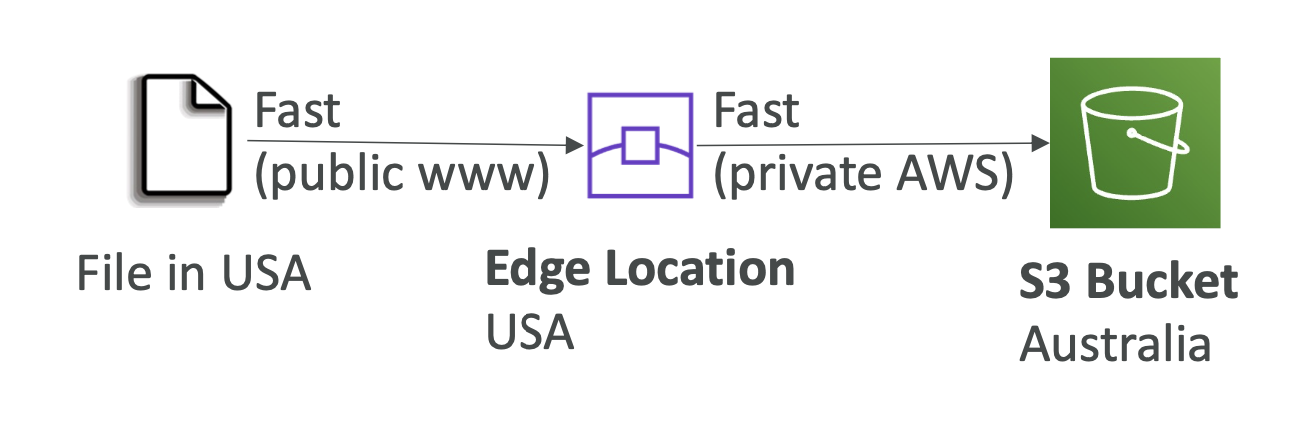
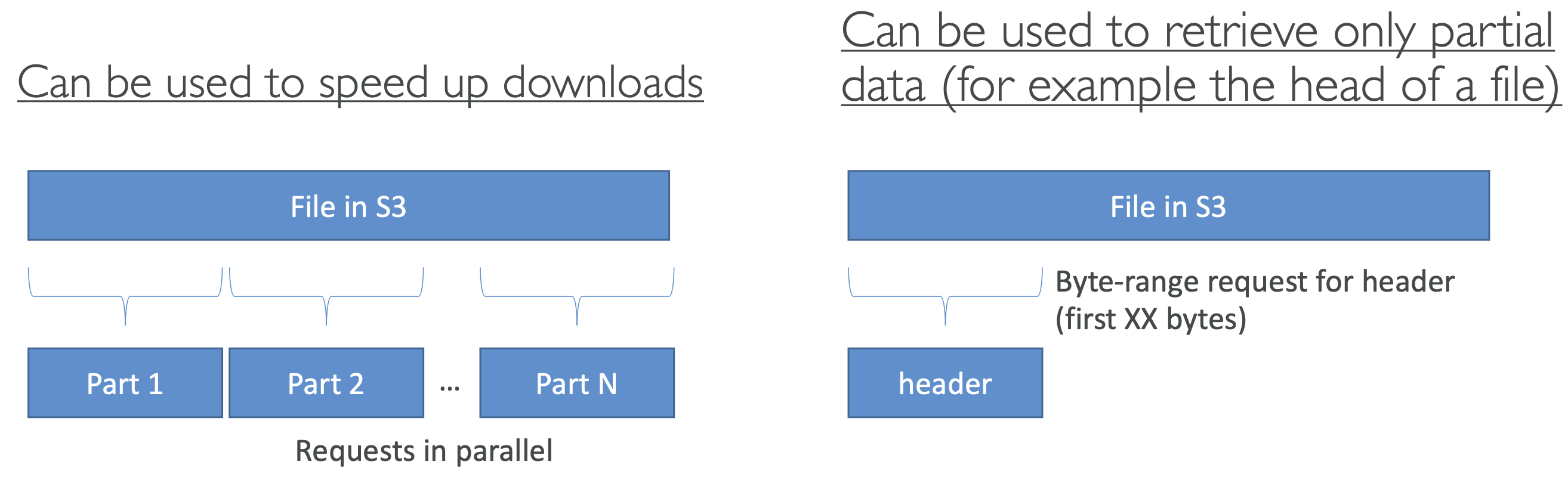
- S3 byte-range fetches: used to speed up downloads by request portions of a file at each time by just using a byte range within the file. Can also just retrieve portions of a file (such as just getting the headers of a file).
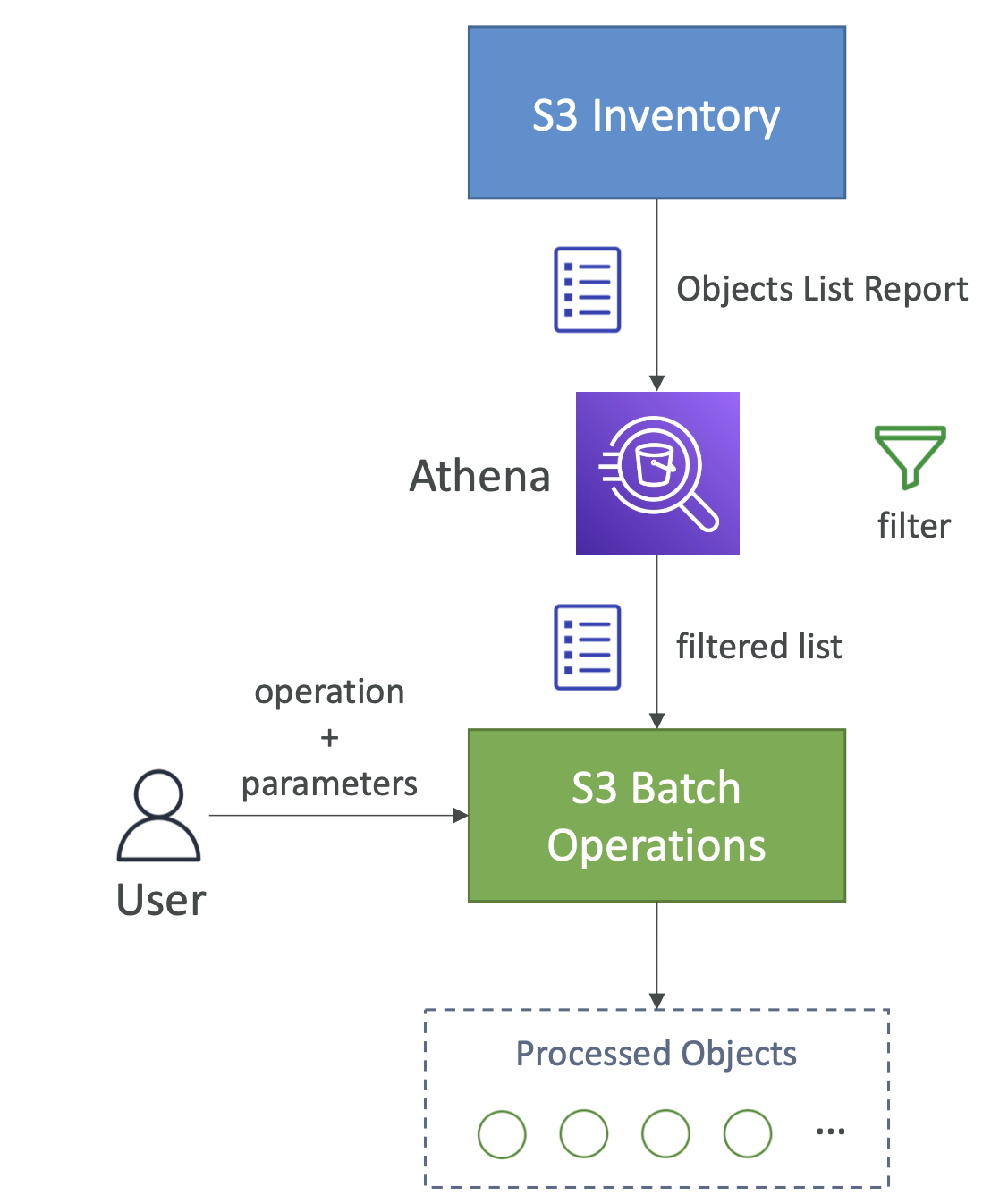
S3 batch operation
This allows you to match update objects in a bucket. Some example operations:
- Modify metadata
- Copy objects between buckets
- Encrypt / unencrypt
- Restore
- Modify ACLs
Batch is useful because it include retries, progress tracking, notificiation completion etc
You can use S3 inventory and Athena to retrieve and filter the objects you want to perform batch operations on.
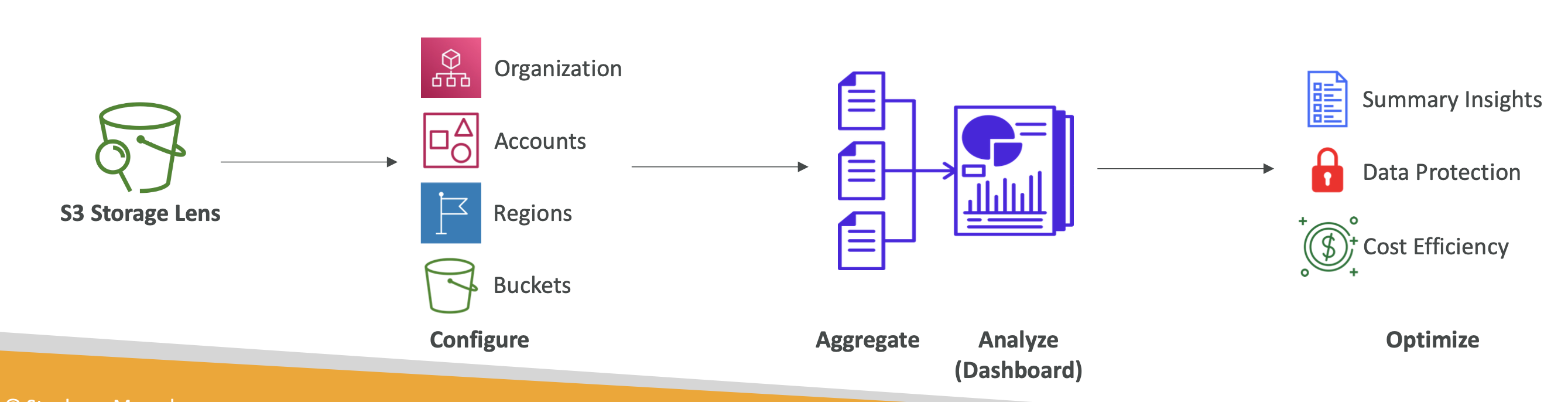
S3 Storage Lens
This tool allows you to analyse and optimise S3 across your org.
It helps uncover anomalies, cost inefficiencies etc
Information can be accessed in a dashboard or exported.
Storage lens metrics
Summary
- StorageBytes, ObjectCount
- use case: identify unused prefixes, find fast growing buckets and prefixes
Cost
- NonCurrentVersionStorageBytes, IncompleteMultipartUploadStorageBytes
- use case: identify buckets with incomplete multipart uploaded older than 7 days, Identify which objects could be transitioned to lower-cost storage class
Data protection
- Find buckets not following data protection best practices
Access-management
- use case: identify object ownership
Also: event metrics, perf metrics, activity metrics and status codes
Pricing
There are 2 tiers: free vs paid
Free: 28 metric available for past 14 days Advanced: advanced metrics: activity, advanced cost optimisation etc. Available for 15 months.
S3 Security
Object encryption
- Serverside encryption (SSE-S3 [default], SSE-KMS, SSE-C)
- Client side encryption
SSE-S3
- AWS manages the encryption
- You never have key access
- "AES-256"
- Enabled by default
- Encryption header must be set when object sent
SSE-KMS
- Allows you to manage your own keys using Key Management Service (KMS)
- Key usage logged in CloudTrail
- Encryption header must be set when object sent: x-amz-server-side-encryption: "aws-kms"
This means you have to make API calls to KMS, which will use KMS quota. You could be throttled
SSE-C
- Encryption keys are outside of AWS
- Keys are transmitted to AWS using HTTPS
- AWS does not store encryption keys
Client side encryption
- AWS client side encryption library can be used to encrypt data on the client before being sent to AWS
- Client fully manages key and encryption cycle
Inflight encryption (SSL/TLS)
- S3 has an HTTP and HTTPS endpoint
- Using HTTPS allows for inflight encryption
To enforce in-transit encryption can be managed by a bucket policy that reject non-HTTPS connections
CORS (cross origin resource sharing)
CORS is a browser security to allow/deny requests to other origins while on the primary origin.
- Same origin: http://example.com/app1 <> http://example.com/app2. The same because they share the same protocol (http) host (example.com) and port.
- Different origins: http://example.com/ <> http://other.example.com/.
The latter example will fail unless to other origin has a CORS Header.
This applies to S3 because requests made to S3 bucket may be denied unless we set CORS header on our bucket.

Within AWS you can control these headers to allow for cross origin requests using a JSON config. Example:
[
{
"AllowedHeaders": [
"Authorization"
],
"AllowedMethods": [
"GET"
],
"AllowedOrigins": [
"<url of first bucket with http://...without slash at the end>"
],
"ExposeHeaders": [],
"MaxAgeSeconds": 3000
}
]
MFA delete
You can force MFA as an additional security measure. Users will have to provide MFA code before:
- Permanently deleting an object
- Suspend bucket versioning
Only root accounts can enable MFA and bucket versioning must be enabled
Deleting with MFA can only be done from CLI, Rest API etc
Access logs
You can log all requests made to your S3 account and analyse the requests, such as with Amazon Athena.
Target logging bucket must be in the same region as the logs bucket.
You can just enable it from AWS and define a log bucket and AWS will handle the rest, including access policies.
Log bucket and target bucket must be separate,otherwise you'll hit a logging loop
Pre-signed URLs
Pre-signed URLs are AWS generated URLs that allow you to pass permissions with URLs.
A use case: You want to give someone else file access, but don't want to make your bucket public. You generate a pre-signed URL, which will contain the permissions of the URL author for PUT and GET requests. The users with the file will be able to access the file if the author permissions allow it.
You can also set a URL expiration.
Best for temporary access to files!
Glacier Vault Lock
Glacier buckets are designed for long term archive storage of objects.
Glacier Lock Vault allows you to store objects once and then not allow deletes, only allowing GET requests.
This is called a WORM model (Write Once Read Many).
The Vault Lock Policy means the object can never be deleted by anyone!
It's important for legal and data retention
There are 2 modes:
- Compliance: no one can delete/modify an object!
- Governance: some users with admin can make changes, so it's less strict
A retention period is the time period for which the protection lasts.
A legal hold protects the object indefinitely, regardless of retention mode and period, however, the mode can be flexibly applied (added, removed etc.)
S3 Access Points
Access points define read/write access to bucket/object prefixes. Instead of having complex access policies, you can instead use Access Points that restrict access depending on object prefix:
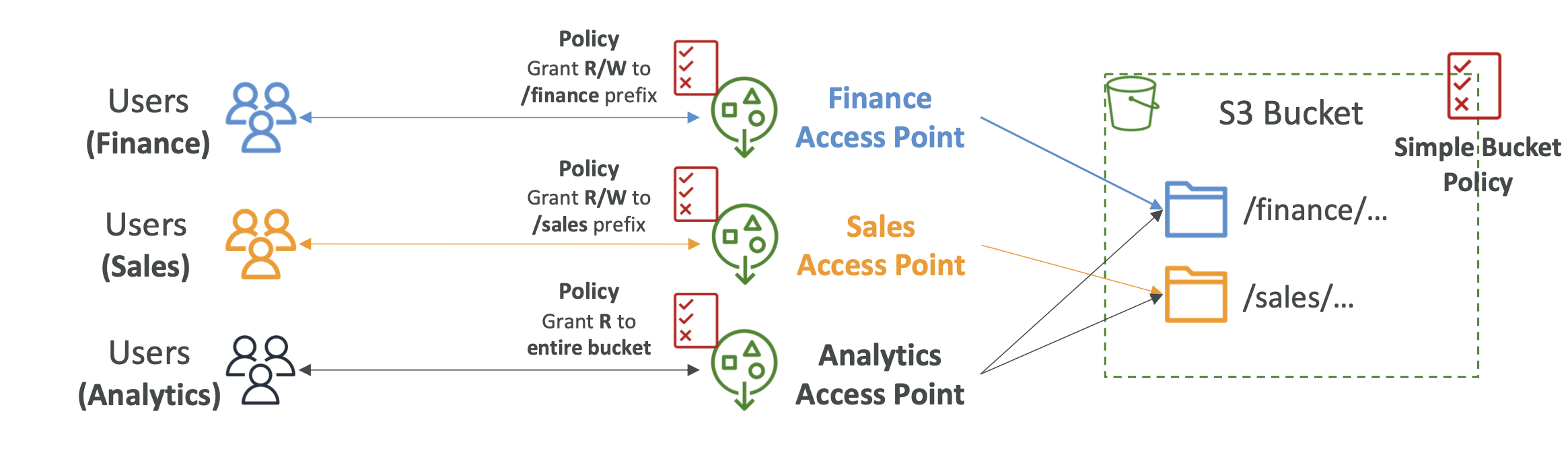
Access points simplify S3 security management
Each access point has its own DNS and access point policy
It can be set at the VPC level as well, so the access point can only be accessible from the VPC
S3 Object Lambda
We can use Lambda functions to edit/update objects on the fly.
We can create an access point that's connected to a Lambda function that edits the object on the fly:
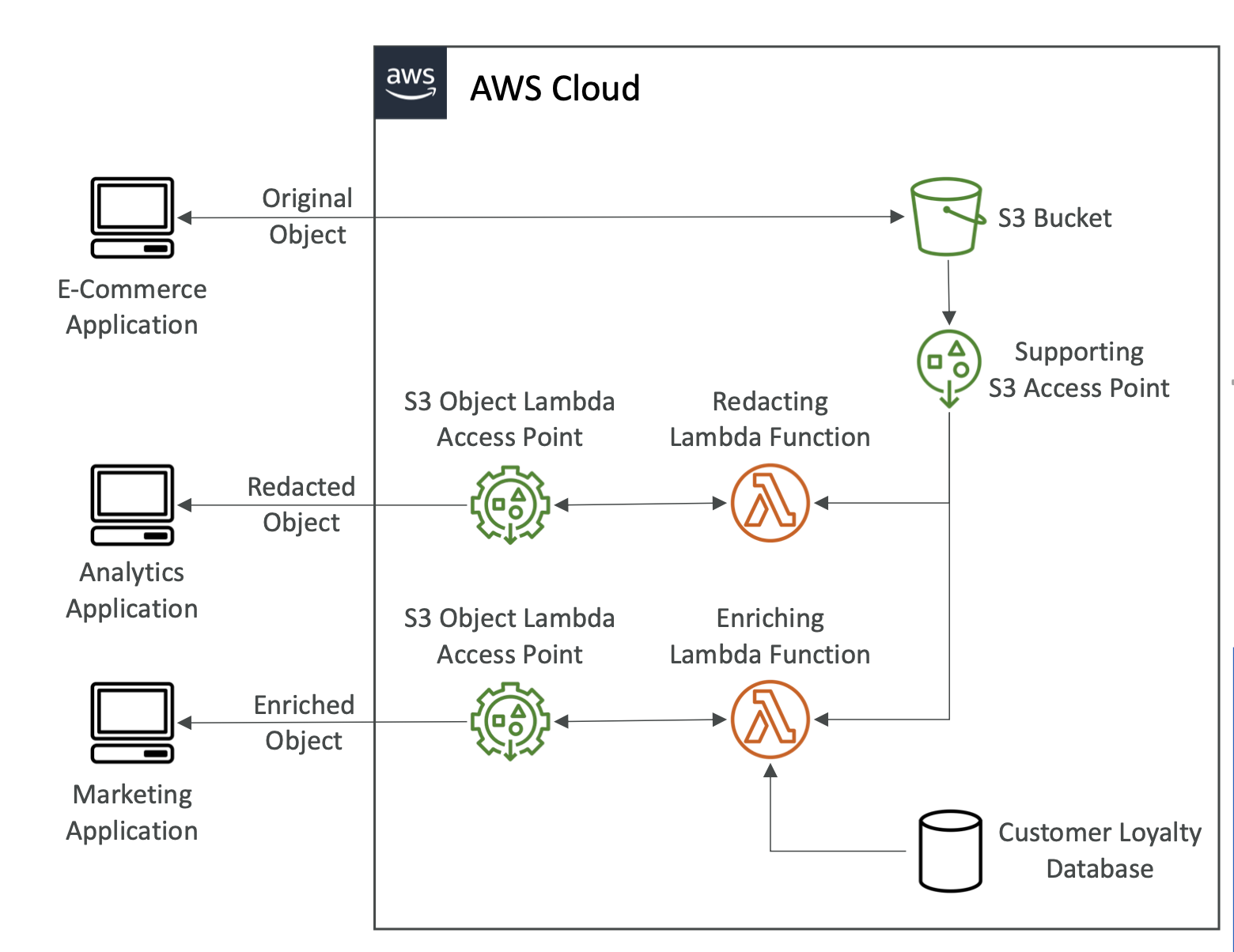
Some use cases:
- Redacting PIM before storage in analytics
- Converting data, e.g XML to JSON
- Resizing and watermarking images
Cloudfront
Cloudfront is AWS' CDN.
It caches content at 216 edge locations around the world.
The benefits are:
- Improved performance (latency)
- Improves UX
- DDoS protection by distributing server load
A list of the locations is here
Origins
These are the information sources that can be used with Cloudfront.
- S3
- VPC (app hosted in private network)
- Any custom origin (HTTP) e.g any public HTTP backend
- ALB
- EC2 instances
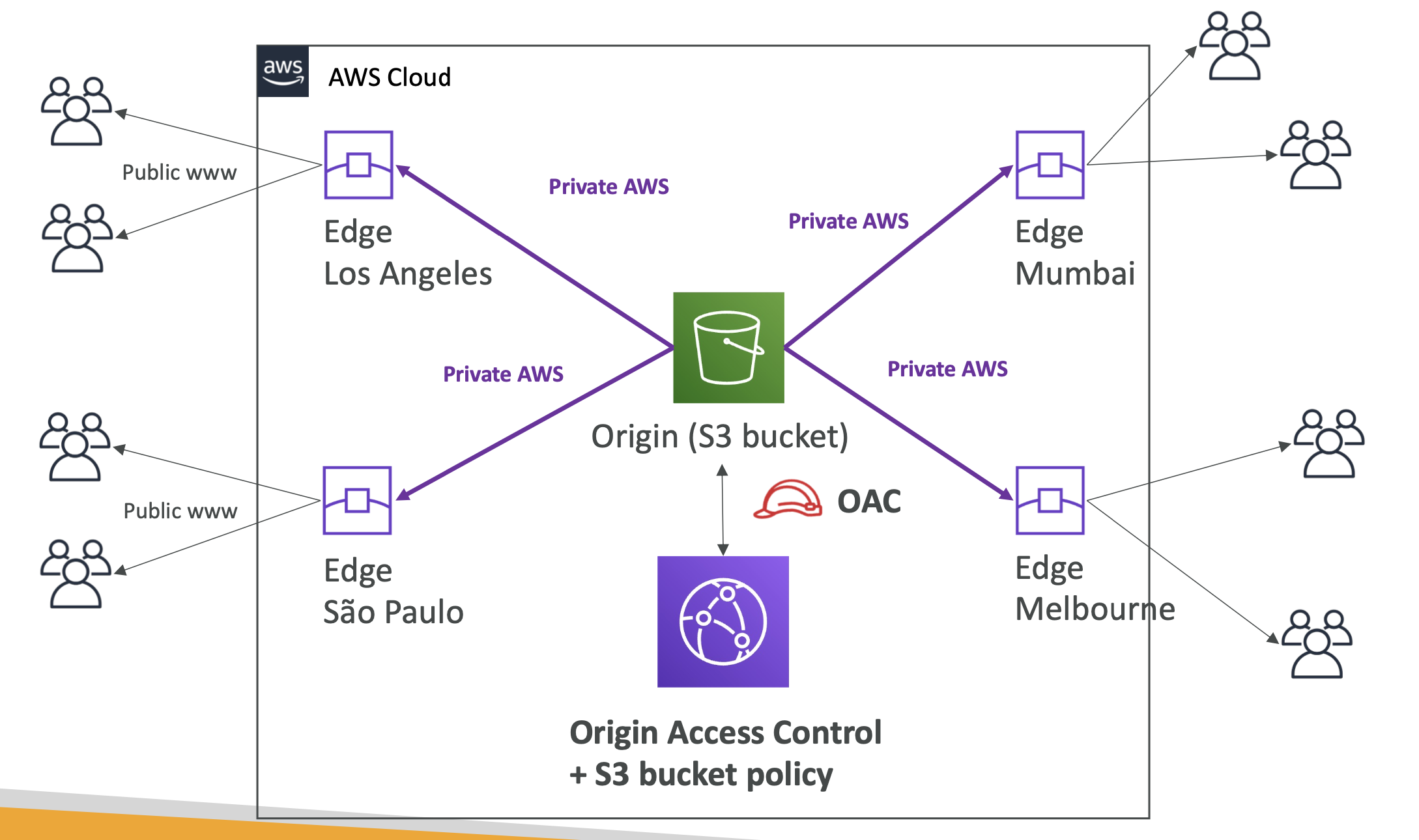
How does it work?
Using S3 as an example:
Cloudfront VS region replication
This is a common question. If Cloudfront manages global access, how do other AWS features that do similar things differ.
Cloudfront:
- Uses the edge network
- Caches files
- Good for static content not changing often
S3 Cross region replication:
- Setup for each region
- Does not cache, files updated in realtime
- Read only
- Good for dynamic content, often changing that needs to be available in a few regions. Not for content that needs to be globally available.
If Cloudfront does not have cached content in the edge location, it will reach out to the origin
ALB or EC2 as origins using VPCs
Using VPC origins allow you to deliver content from apps hosted in private subnets.
Traffic can be delivered to private ALBs, NLBs and EC2 instances
You can choose what to expose through Cloudfront, which is highly secure
Georestriction
Can setup an allow list for a list of approved/banned countries.
IPs are mapped to Geolocations internally by AWS.
Pricing
Cost per location varies. E.g Mexico and US are much cheaper than India (surprisingly).
Price classes
You can reduce cost by reducing the number of edge locations:
- All: all regions, best performance
- 200: most regions, less expensivr
- 100: least expensive regions
Cache invalidation
If you change origin, Cloudfront won't update content until TTL expires.
You can force the change using Cloudfront invalidation, which will remove files from the cache.
Global accelerator
To further reduce latency, global accelerator accelerates a user through the network. This prevents many hops:
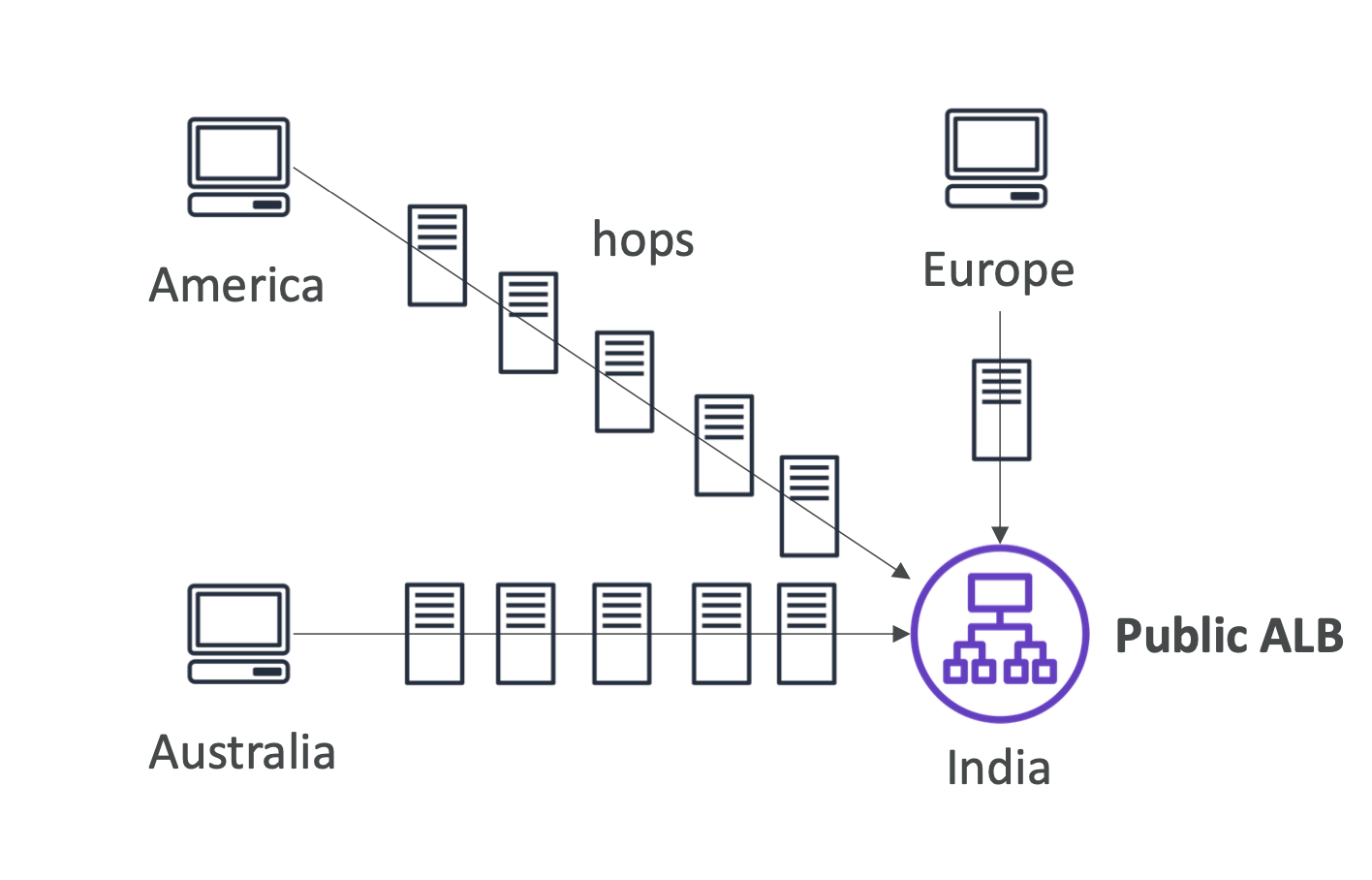
It does this by utilising Anycast IP, which gives multiple servers the same IP, but routes the user to the nearest one:
Global accelerator uses the Anycast IP to achieve acceleration.
Benefits:
- Lowest latency and regionla failovers
- No issue with client cache
- Works on internal AWS network
- Health check compatible
- Secure because only 2 external IPs exposed
- DDoS protection
Docker professional certificate
Docker intro
Docker solves the "it doesn't work on my machine" problem. This problem occurs when software that was developed within a certain environment doesn't work / leads to unintended behaviours on aanother machine.
This often occurs because:
- The different machines have different tooling
- Different configurations
- Missing hardware dependency / files
Tools to address these issues include Chef, Puppet and Vagrant, although they rely onm hardware and OS knowledge.
Docker takes a simple approach by packaging into virtual OS configured with just enough to run the app and nothing else
It's analagous to cooking a meal vs cooking at someone else's house. Your favourite recipe tastes great when you cook it with your own utensils, with your own stove and setup. But emulating it elsewhere leads to a completely different experience. Docker lets you package up your setup and emulate the cooking experience at someone else's house.
Containers vs virtual machines
There is a common misconception that container are the same as virtual machines (VMs), but this is wrong.
Containers virtualise OS kernels, whereas VMs virtualise hardware.
Virtual machines
- Use hypervisors to emulate real hardware
- Take up loads of space
- Require OS installation from user
- Cannot interact with host machine
- Can run multiple apps
Containers
- Do not emulate hardware
- Uses same OS and hardware as host machine
- Do not require OS install
- Take up less space
- Can only run 1 app at a time
- Can interact with host
Containers explained
A container is composed of two main things:
- Namespaces
Namespaces partition system resources and limits what a Docker project can see.
For example, a namespace can have a program think it's running as the root super user, with file system access, whereas it's really running as a specific user with limite privileges.
- Control groups
Control groups limit how much you can see. This is a Linux kernel feature that limits how much hardware each process can use. Docker user control groups to:
- Monitor and limit CPU usage
- Monitor and restrict network and disk bandwiddth
- Monitor and restrict memory consumption
Control groups help Docker containers not use up too much system resources, like a VM would
Limitations/considerations
- Because namespaces and control groups are Linux features, this means Docker only runs natively on Linux.
- Container images are bound to their parent OS. Meaning an image made on Linux can only run on a Linux machine, same for Windows, Mac
Other containers
Containers have been around for a long time, as far back a 1979 with chroot(): (https://www.redhat.com/en/blog/set-linux-chroot-jails)[https://www.redhat.com/en/blog/set-linux-chroot-jails] and other things like BSD jails and Solaris zones, and most recently Linux containers: https://linuxcontainers.org/lxc/getting-started/
Docker advantages
- Docker makes configuring and packaging apps and environments much easier.
- Makes sharing images really easy with Docker hub
- Docker CLI makes starting apps in containers simple
CLIs
The CLIs and their commands often are documented below.
Certbot
This program allows you to generate SSL certificates and assign them to domains.
Generate SSL certificates for all/selected domains:
$ certbot --nginx
For specific domains
$ certbot --nginx -d domain1.com
For multiple domains
$ certbot --nginx -d domain1.com -d domain2.com
Jrnl
Jrnl lets you journal from the command line.
To add an entry:
jrnl Went to church. It was divine.
This will store an entry for today. "Went to church" will be the title (anything up to . is considered the title)
To see journal entries for today:
jrnl -on today
Taskwarrior Commands
Taskwarrior lets you manage tasks from the command line.
You can segment tasks per project (personal, work etc).
Commands
Tasks are managed with the task command.
List tasks
task list
Tasks are assigned an id which can be used when managing that task.
Add tasks
task add "do the washing"
Tasks will be set to the current context
Complete task
task done 12
Set context
task context work
Add priority
task add "build CLI tool" priority:H
Update task priority
task modify 12 priority:H
Programs
The programs I use are below.
Vim
Visual mode
Select to line number
Move to the line, shift + v to select the line.
Find the line number you want to select to, for example 35. 35G will select to that line.
Elasticsearch
Elasticsearch
Elasticsearch
This course focuses solely on Elasticsearch, not the total ELK stack (Elastic, Logstash, Kibana).
What is ElasticSearch?
Elasticsearch is an open source analytics and search engine.
Some use cases include:
- Full text search across a product catalogue
- Querying and analysing structures data such as logs or analytics
- Application Performance Management (APM) is a specific use case where you store logs in Elastic and visualise them to monitor application performance (such as a CPU/RAM)
- Send events to ElasticSearch. E.g send sales from physical stores to ElasticSearch
ES is written in Java and is build ontop of Apache Lucene.
How does Elasticsearch work?
Data is stored as documents in ES. A document represents a row in a database and contains fields similar to columns in relational databases.
A document is just a JSON document.
To query these documents we just use a REST API. The query and the document are both JSON objects.
Elastic stack
ELK stack
The Elastic Stack refers to all the products within the Elastic offering.
This three core componets of this are:
- Elasticsearch: the core of Elastic
- Logstash: an events processing pipeline
- KKibana: data visualisation tool
This is commonly referred to as the ELK stack. However, there is more to Elastic and the ELK stack is common parlance as these three tools are often used together.
Elastic stack
The true Elastic stack has more offerings, however, including:
- Beats: used for data ingestion, it sends data to Logstach or Elasticsearch
- X-Pack: a set of ES extensions that adds auth, security, alterting and ML capabilities
The Elastic stack is a superset of the ELK stack
Put loosely,
- Beats and logstash are used for data ingestion
- ElasticSearch searches analyzes and stores data
- Kibana visualises data
- X-pack adds features to the stack
Opensearch vs Elasticsearch
Elasticsearch was originally released as an open source project under the Apache License 2.0, but a paid license was required to use additional feautes, such as security, monitoring, ML etc under the Elastic License.
In 2015, AWS released "Amazon Elasticsearch Service", which was a managed Elasticsearch service on AWS.
This led to trademark infringements on AWS. AWS also offered additional ES offerings such as those required under the Elastic license under "Open Distro".
In 2019, ES sued AWS for trademark infringements and released a new license in 2021 (SSPL), which meant that cloud providers couldn't offer a managed ES service without contributing to the original project.
AWS forked ES as of version 7.11 and maintain their own version that they offer under "Opensearch".
Hosting options
There are a few hosting options:
Elastic/Opensearch on Bonsai or another hosted service
Offerings like Bonsai will manage your ES cluster for you
Elastic Cloud
This is ES's native offering and lets ES manage your deployment for you.
Elastic serverless
ES also have a serverless option. This offering autoscales and is stateless and is optimised for realtime applications.
It eliminates the need for node and shard management, capacity planning etc by decoupling compute from storagfe and indexing from search.
Self hosting
You can also self host ES on your own machines. You can download ES here.
It will download two archives, one for ES and one for Kibana in separate directories.
It ships with dependencies like Java(ES) and Node.js (Kibana).
Useful Elastic command
Remove Mac gatekeeper signature from .tar download
xattr -r -d com.apple.quarantine <elastic-path>
Extract kibana and ES .tar archives
tar -xvf <path>
Reset elastic user password
bin/elasticsearch-reset-password -u elastic
Generate new Kibana token
bin/elasticsearch-create-enrollment-token --scope kibana
Generate new Node token
This is useful for when spinning up new nodes in our cluster.
bin/elasticsearch-create-enrollment-token --scope node
Know why shards are unassigned
GET /_cluster/allocation/explain
Check shard health
GET /_cat/shards?v&index=*,-.*,-.internal.*,-.*default*
You will see doc distribution across shards in the response:

Elasticsearch architecture
ES used a distributed architecture to maintain performance and availability.
The core concepts behind ES architecture are: clusters, nodes, indices and documents.
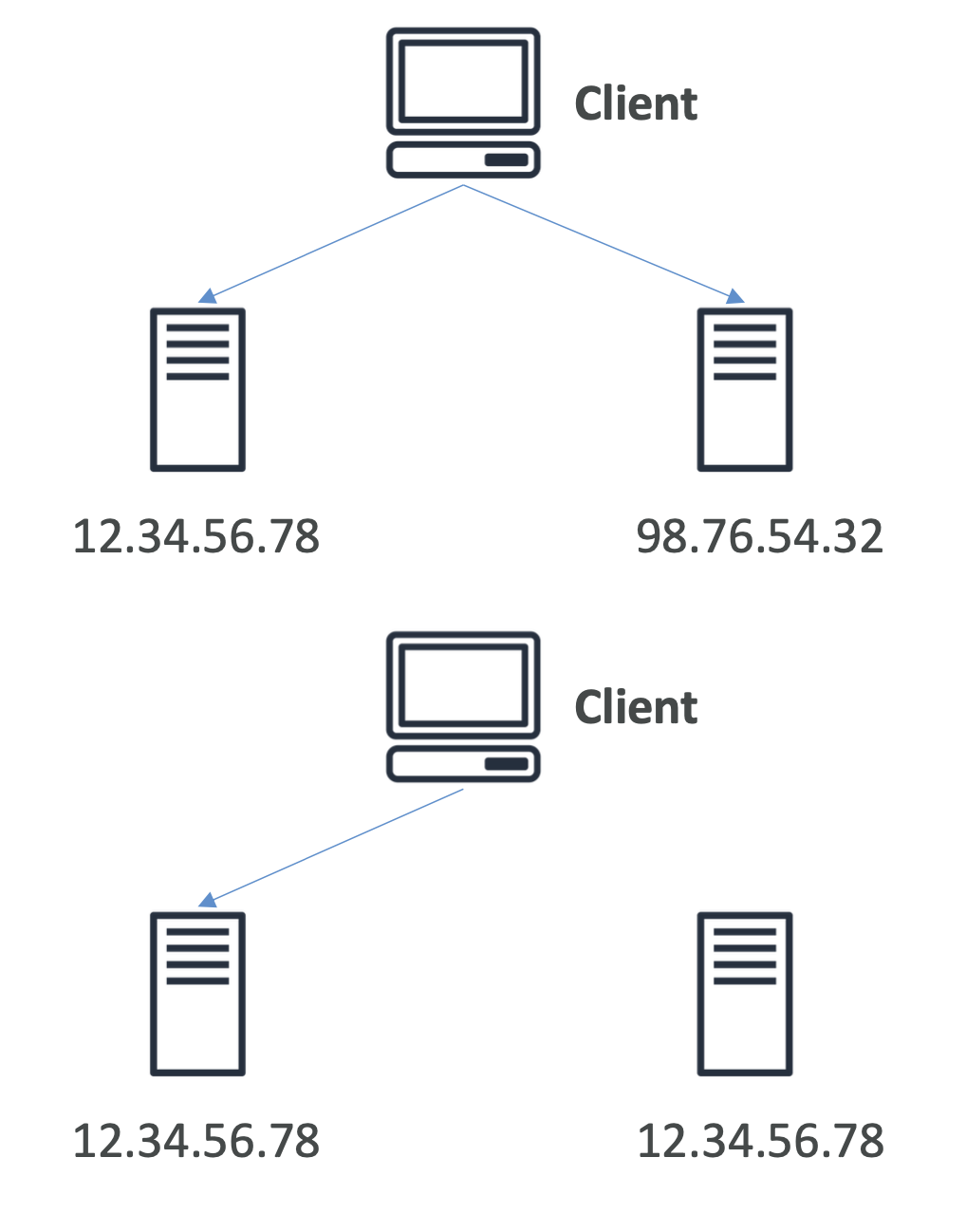
Clusters
A cluster is a collection of nodes. Clusters can house one of multiple nodes.
When you spin up ES, a cluster is automatically created.
Typically, one cluster is enough, but you can have multiple clusters for separation of concerns if needed.
Nodes
A node is an instance of Elasticsearch. You can operate with one or multiple nodes.
For high volume application, you typically want many nodes.
Nodes are able to communicate with one another and nodes can be of a particular type to perform specific tasks within the cluster (for e.g there can be a data node for storing data and a query node for querying data).
Nodes are what store data in ES.
Indices
Indices are collections of document. Indice are the logical way in which to organise collections of documents. For e.g in a movie example, there could be an index for actors, an index for directors and an index for movies themselves.
Indices aren't separated on disk, indices are just references to logical collection of documents. Indices are a logical abstraction, under the hood they are split into shards.
Documents
Documents are just JSON object that represent a single entity.
Debugging Elasticsearch
This isn't part of the course, but we'll use this section to document various debugging session during the course.
Kibana cannot connect to Elasticsearch
I ran into this error while trying to startup Kibana for the second time:
[elasticsearch-service] Unable to retrieve version information from Elasticsearch nodes. Request timed out
This suggests Kibana cannot connect to ES.
Firt check if ES is running:
curl localhost:9200/
If there is an empty response, it means Debugging
CURL queries
Some examples of running ES querie using CURL from the command line.
Authentication
For local deployments it's common to run into Authentication issues when querying endpoints.
note that from version 8 onwards, ES forces HTTPS
curl -X GET https://localhost:9200
This will throw a cert error. When ES is initialised, certificates are created. So we need to specify them as part of our cURL command:
curl --cacert config/certs/http_ca.crt -X GET https://localhost:9200
certificates are stored in $ES_HOME/config/certs.
This will still error with missing authentication credentials for REST request.
Requests must be authenticated. We can use the user and password for this:
curl --cacert config/certs/http_ca.crt -u elastic -X GET https://localhost:9200
This will prompt for a p/w, but you can also add the password to the request like so:
curl --cacert config/certs/http_ca.crt -u elastic:<your-pw> -X GET https://localhost:9200
It's better to set your password in the terminal as an environment variable:
export ES_PW = "your-password"
curl --cacert config/certs/http_ca.crt -u elastic:$ES_PW -X GET https://localhost:9200
Check the variable has been included with printenv.
Index search
Search an index (products) for all documents:
curl --cacert config/certs/http_ca.crt -u elastic:$ES_PW -X GET -H "Content-Type:application/json" https://localhost:9200/products/_search -d '{"query": { "match_all": { } }}'
the -d flag is for sending a body with the request in JSON form.
Sharding and scalability
Sharding is the practice of splitting indices into smaller chunks. This allows you to scale data volume horizontally.
ES Shards are at the index level and each index is comprised of one or more shards. An index can have many shards, but a shard can only belong to one index.
ES is built on top of Apache Lucene and technically, each shard is an instance of Lucene, which is comprised of an inverted index.
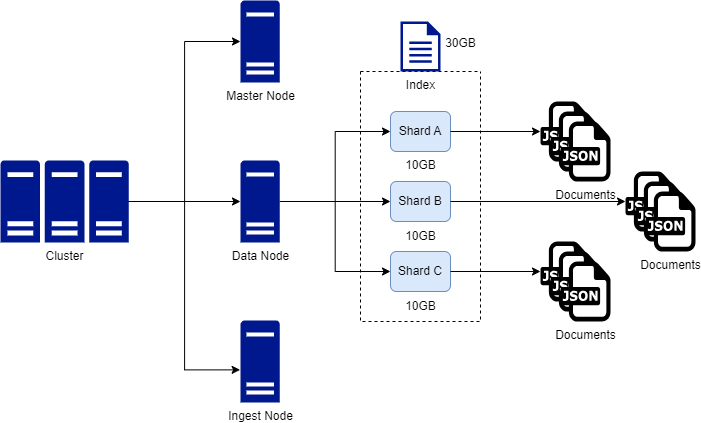
ES Sharding example
Say we have two ES nodes each with a 500GB capacity. We also have a index that is 600GB. This index won't be able to fit onto either node, so we can splut the index into multiple shards and place each shard onto a node.
Purposes
- To store more documents
- Fit large indices onto nodes
- Improve performance through query parallelization (search happens at the shard level, so searches can be run across multiple shards at once)
Tech details
- Prior to
V7.0.0ES created indices with 5 shards automatically - Now an index only contains 1 by default to prevent over sharding
- You can increase # of shards with Split API
- You can decrease # of shards with Shrink API
The optimal number of shards really depends on the use case, but you should plan sharding in alignment with data size across the cluster
Replication
Replication in ES is the process of duplicating data for the purpose of fault tolerance to avoid losing data.
Replication is done at the index level and involves creating a copy of shards, called replica shards. A replicated shard is a primary shard.
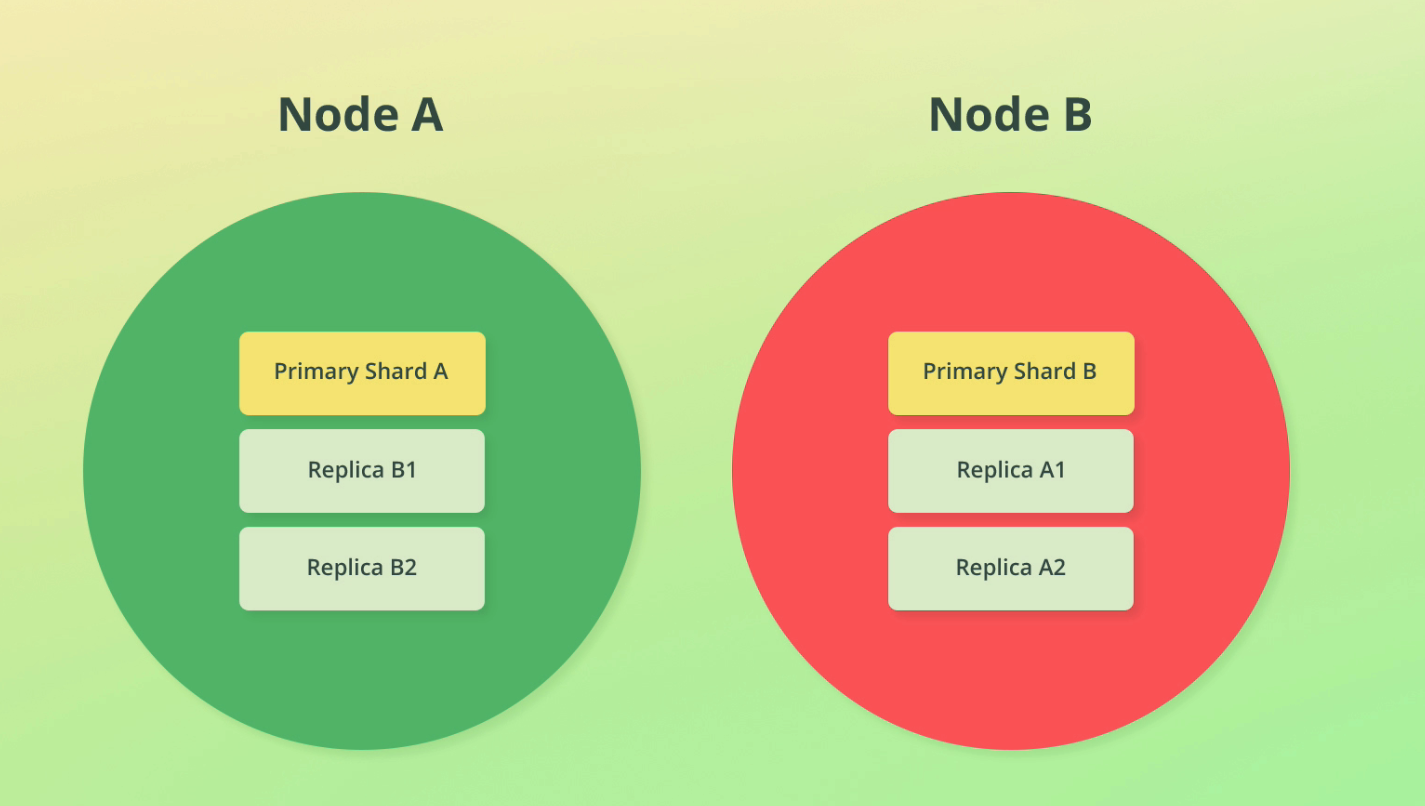
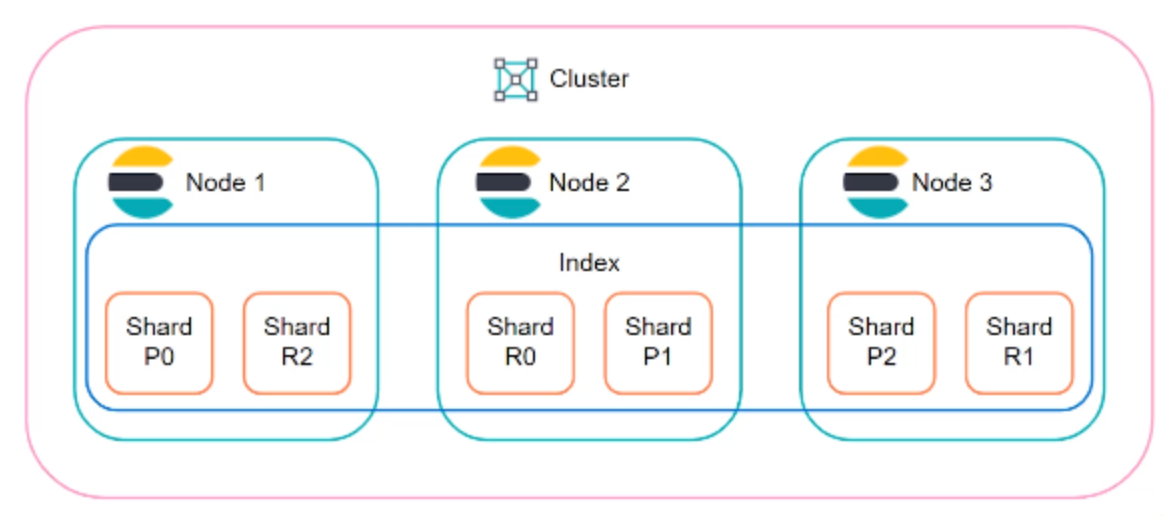
If we replicate shards across nodes, we can introduce fault tolerance if the nodes are on different machines. See this discussion on single server vs multi server implem.
Replicate shards once for non critical systems, replicate twice for critical systems
A replica is never allocated to the same node as its primary shard. If we only have 1 node and we create a replica, that index will have nowhere to go, so it will get a YELLOW status
To see a list of shards use the following command:
GET /_cat/shards?v&index=*,-.*,-.internal.*,-.*default*
(note the query params are for only showing non-internal indices)
Output:

We can see the replica shard is unallocated because we only have 1 node.
Replication group
A replication group is simply a primary shard's replicas and the primary shard as well.

Throughput
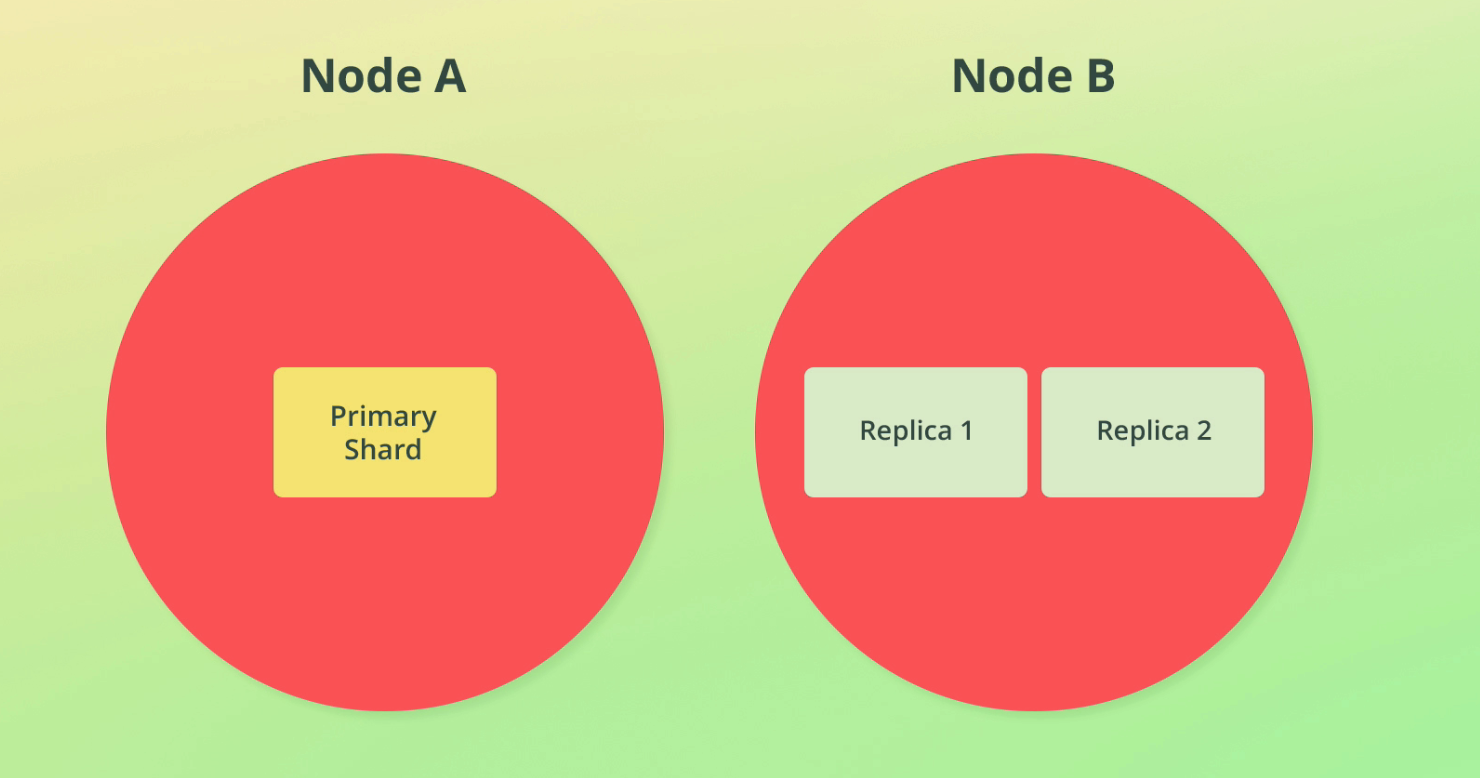
Replication can also help with throughput. A replica shard can be queried just like a primary shard (in fact, ES will route requests to the best shard to query).
Below you can see we have three shards across two nodes - this means if 3 requests come through at once, we can spread the load across the shards and achieve parallelization.
Snapshots
Snapshots allow backups to a point in time. They can snapshot:
- Specific indices
- Clusters
Replication is best for fault tolerance for the current state, whereas snapshots are best for historical backups and getting things back to a working state.
Adding nodes to an ES cluster
As we previously learned, sharding increases our data capacity by breaking down data into smaller chunks to fit onto nodes.
However, this won't scale forever, and as data grows, eventually we will need to add new nodes to our cluster.
How to add new nodes
To add a new node to our cluster, we can simply extract another version of the es .tar we downloaded.
Assuming we have kibana and an existing ES node in a the directory elasticstack, just add two new instances to the directory:
tar -xvf elasticsearch-9.0.3-darwin-x86_64.tar.gz
Do this twice into two folders: node-2 and node-3.
We need to generate an enrollment token for these new nodes. This enrollment token is generated from the existing (usually initial/primary) node in the cluster:
bin/elasticsearch-create-enrollment-token -s node
Then use this token when initialising the new node:
bin/elasticsearch --enrollment-token <TOKEN>
The function of this enrollment token is used by the new node in the cluster to automatically configure:
- Cluster names
- CA certificates
- Initial connection settings
- Bootstraps communication within the cluster
Outcomes
Take this scenario:
- You have created a single ES node in a cluster
- This has generated a number of internal indices
- You have created a replica shard for an index
As we only have 1 node running, the internal indices are all primary indices with no replication. The replica shard is unassigned because it doesn't have another node to go to. Our cluster will have a YELLOW status because of this.
Remember replica shards have to be on a separate node to the primary shard
When we create a new node on the cluster three things will happen:
- The replica shard will be assigned to the new node
- Internal indices will have auto generated replica shards because replica indices have a setting
index.auto_expand_replicas: 0-1. - Cluster health will change from YELLOW to GREEN
Adding a third node
Note that adding a third node to the cluster has some considerations, namely that once you start a third node, you can never have less than two nodes moving forward.
So if you ever want a singe node cluster again after starting a third node, this is technically not possible.
This has to do with how ES assigns and uses master nodes. But we won't go into that detail.
Elasticsearch automatically assigns and balances shards to nodes for you
When a node leaves
When a node leaves the cluster, it can take some time for shards to be reassigned to a node.
You can read more about this, including why this can take some time, here.
Node roles
As we know, an ES cluster consists of one or multiple nodes. Nodes typically contain shards, but this isn't always the case.
This is because nodes can be assigned different roles that do different things. The roles are:
- Master-eligible: A node may be elected as the master node. A master node do cluster wide actions such as shard allocation, creating and deleting indices etc. This role doesn't mean the cluster will be the master, just that it is eligible. There is a voting process for this.
- Data: The data role means the node stores data and performs queries related to the data on that node.
- Ingest: The ingest role enables a node to run ingest pipelines (like adding documents to indices). You can think of this as a simplified Logstack pipeline, but for full functionality, Logstash is better. Ingest roles are best for relatively simple operations.
- Machine learning: The ML role role allows the node to run jobs and machine learning API requests that don't affect other tasks.
- Coordination: The coordination role coordinates queries across the cluster. It doesn't run queries, just delegates the task to other nodes. Note that every node is a coordination node, however for a node to be a dedicated cooordination node, it has to have an empty role list []. There is a section on that here, this is typically best for large clusters that need some load balancing.
- Voting only: Not that important, but read more here
To see node roles:
GET /_cat/nodes?v

When to change node roles
- When optimising the cluster to scale requests
- Often something done for large clusters
Typically, changing nodes, shards and replicas is something you'd do before resorting to changing node roles
Never change roles unless you are sure what you're doing!
Managing data
Deleting indices
Delete an index called pages:
DELETE /pages
Adding indices
To add an index called products:
PUT /products
we can pass in a JSON object as well, defining # of shards and replicas:
PUT /products
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 2
}
}
Indexing documents
POST /products/_doc
{
"name": "Coffee Maker",
"price": 64,
"in_stock": 10
}
Retrieving docs by id
Here with the ID of 100.
GET /products/_doc/100
Retrieving all docs in an index
Here we need to use the search endpoint:
GET /products/_search
{
"query": {
"match_all": {}
}
}
Updating docs
POST /products/_update/100
{
"doc": {
"in_stock": 3
}
}
Adding new fields to docs
Here we use the update API. Something to note about this API is that it replaces the document, it doesn't update it in situ.
POST /products/_update/100
{
"doc": {
"tags": ["electronics"]
}
}
Documents are immutable in ElasticSearch, meaning they are deleted and reindexed
Scripted updates
Reduce stock count by 1. ctx is a special variable that allows us to access the source of the object. ctx._source allows us to access the source of the object we want to update.
POST /products/_update/ig5mHpgBorYWjN5fK4m0
{
"script": {
"source": "ctx._source.in_stock--"
}
}
Update the stock value
POST /products/_update/ig5mHpgBorYWjN5fK4m0
{
"script": {
"source": "ctx._source.in_stock = 11"
}
}
Using params in scripted updates
We can also pass params that can be used in our updates.
For e.g: if customer purchases 4 products this means we can access this value in our script and use it programatically to reduce stock by 4:
POST /products/_update/ig5mHpgBorYWjN5fK4m0
{
"script": {
"source": "ctx._source.in_stock -= params.quantity",
"params": {
"quantity": 4
}
}
}
You can add conditional scripts to the source using multiline, for e.g skip an update if the stock count is already 0:
if(ctx._source.in_stock === 0) {
ctx.op == 'noop'
}
noop means 'no operation' and will skip the update.
Upsert documents
Upserting documents means to update and insert a document based on whether it exists. If it already exists, a script is run, if not, the doc is indexed.
It still uses the _update API:
POST /products/_update/101
{
"script": {
"source": "ctx._source.in_stock++"
},
"upsert": {
"name": "Blender",
"price": 399,
"in_stock": 5
}
}
This example updates the stock of document 101 if it already exists, otherwise it creates a new document with the upsert body.
Replacing documents
PUT /products/_doc/101
{
"name": "Toaster",
"price": 500
}
Deleting documents
DELETE products/_doc/101
Updating multiple docs by a query
Similar to updates with a WHERE clause. i.e find docs based on a condition and then update them.
We use the update_by_query endpoint with an attached query clause:
POST /products/_update_by_query
{
"script": {
"source": "ctx._source.in_stock--"
},
"query": {
"match_all": {}
}
}
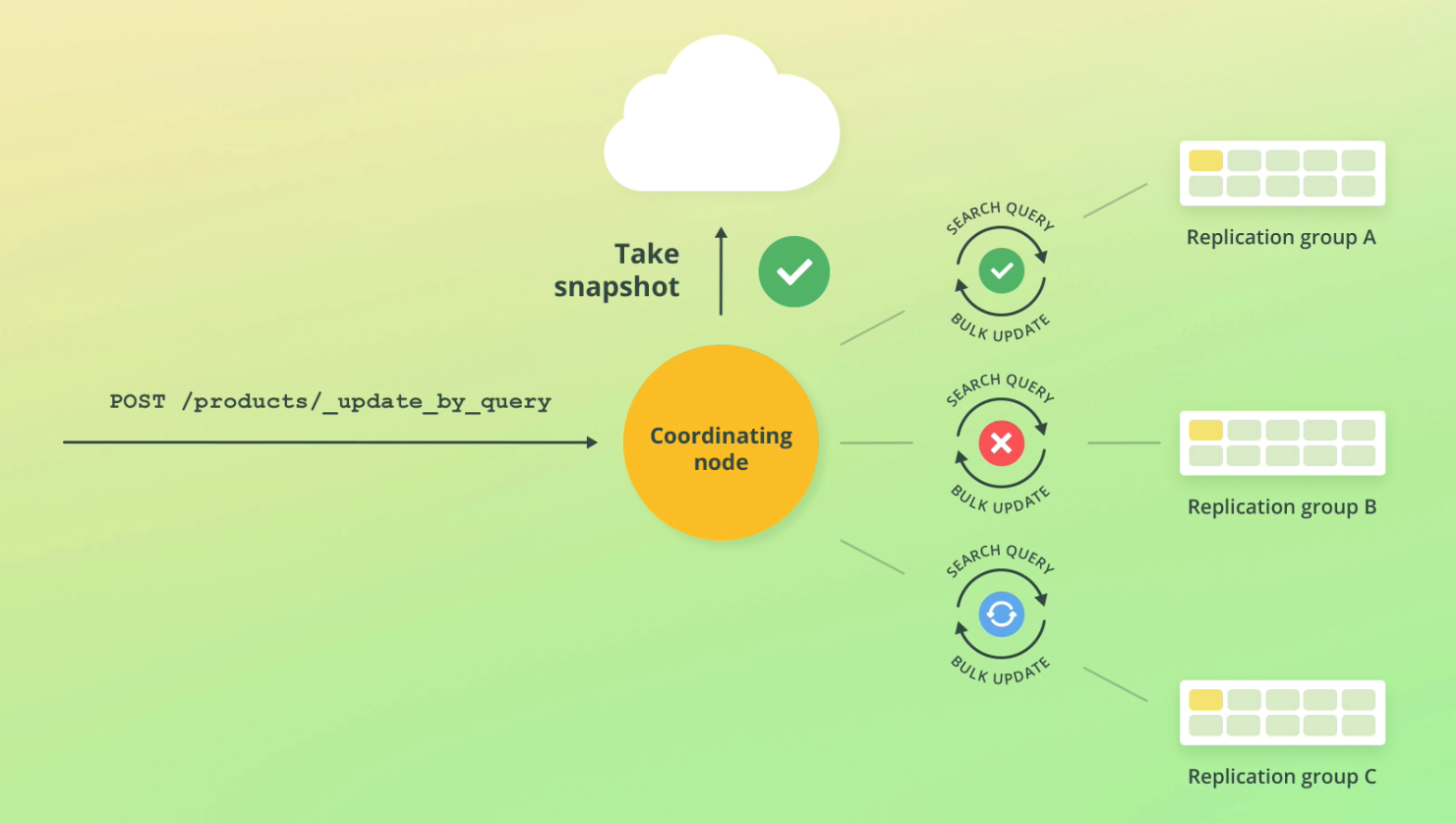
When ES runs bulk updates it takes an index snapshot is created in order to handle failure cases. ES have a retry mechanism built in as well. If an error occurs, the request returns, but the updates that have occurred remain.
As bulk updates can take some time, there may be changes that have occurred while you run the bulk update. This means the query will fail due to conflicts.
You can override this with "conflicts": "proceed".
More on this topic here
Deleting multiple docs by a query
POST /products/_delete_by_query
{
"query": {
"match_all": {}
}
}
Bulk CURL request
curl --cacert ~/elasticstack/elasticearch/config/certs/http_ca.crt -u elastic -H "Content-Type: application/x-ndjson" -XPOST https://localhost:9200/products/_bulk --data-binary "@products-bulk.json"
Index vs create actions:
- Create actions fail if docs already exist
- Index action will add doc if already exists, otherwise it replaced
Routing
As we shard our indices in ES, the question arises how does ES know where to store documents? In which shard?
Also: how does ES know from which shard to retrieve our documents when a query is performed?
The answer is routing.
Routing is the process of resolving a shard for a document, for both indexing and retrieval
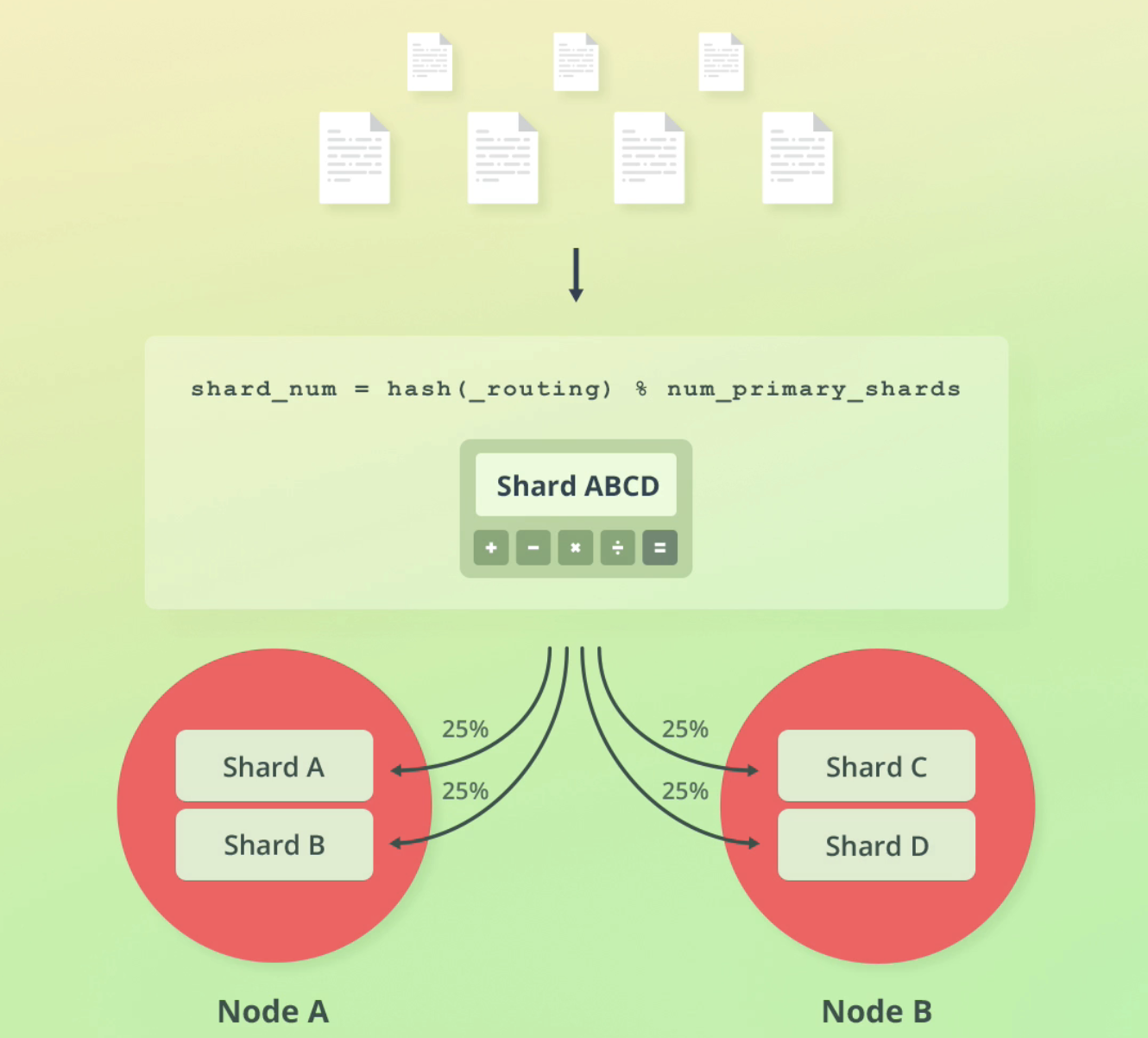
Routing formula
ES uses a simple formula to determine which shard to reach out to:
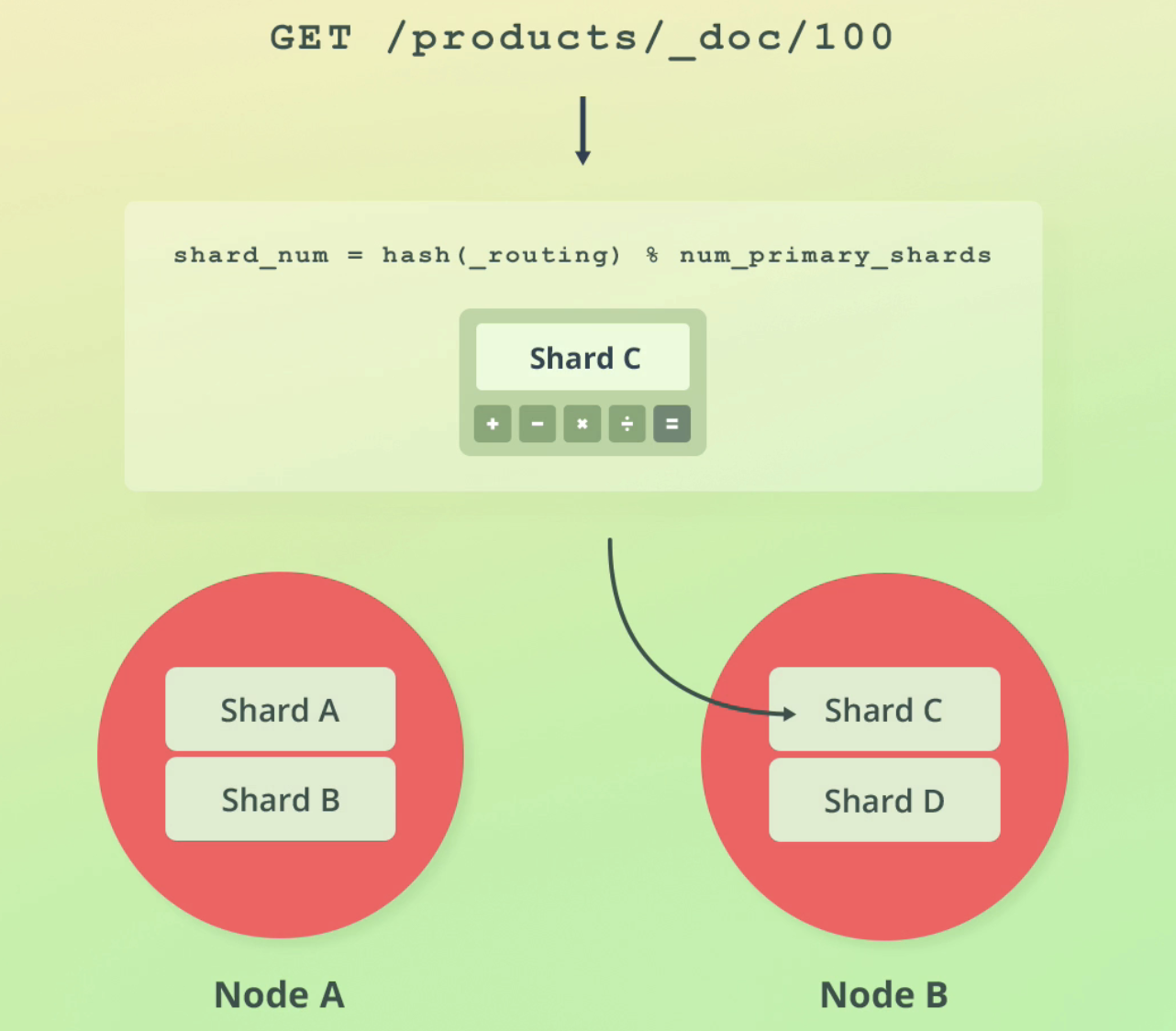
A benefit of this formula is that ES handles this all for us and documents are distributed evenly amongst our shards without our input:
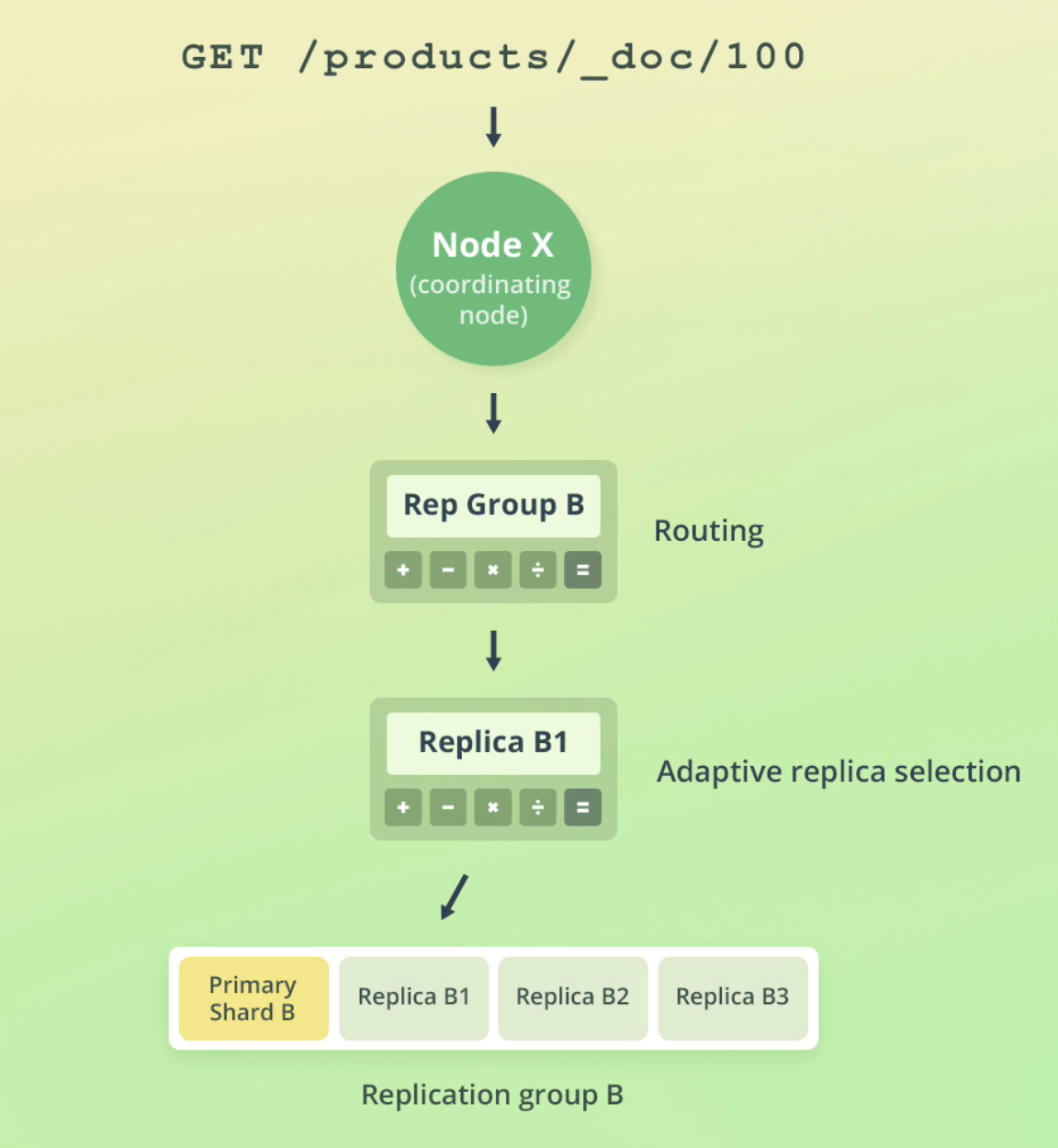
How ES reads data
How ES writes data
First, ES routes the request to a replication group. But after that, it routes the request to the primary shard, which is responsible for:
- Validating the request
- Writing the data locally
- Forwarding to replica shards in paralell
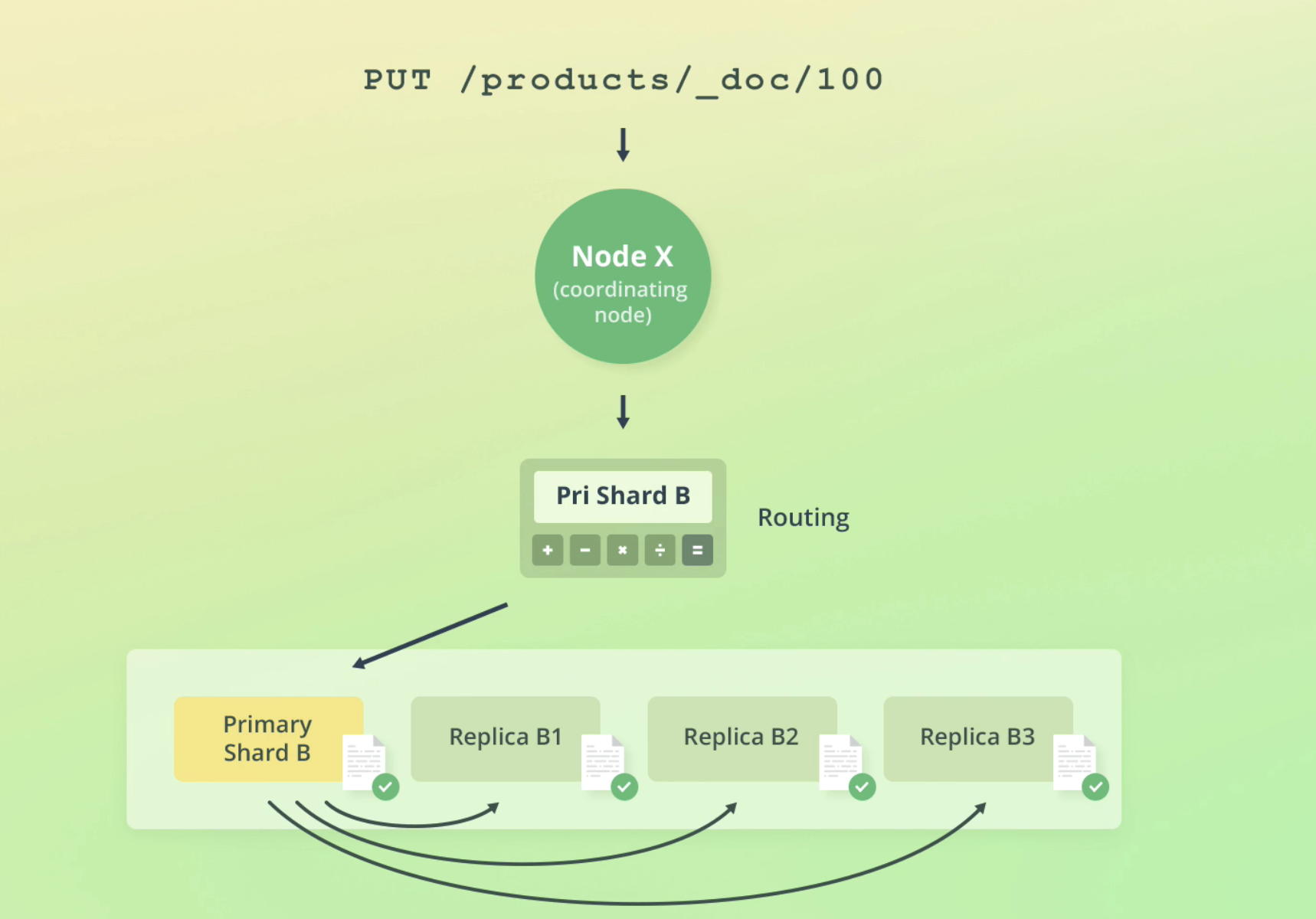
Writing data is always routed to the primary shard, validates the data, stores locally then onsends to replicas
How ES handles write failures
If failures occur, let's say for example, when the primary shard goes down, ES initiates a recovery process. We won't go into too much detail about the recovery proces, but there is one main topic to understand:
Primary terms and sequence numbers
Primary terms is a way to to distinguish between old and primary shards. For e.g is a primary shard fails, a replica is promoted to primary and the primary term counter is increased by 1.
Sequence numbers is a counter that is incremented for each operation until the primary shard changes. This lets ES know which order operations occurred on a primary shard.
Both primary terms and sequence numbers are used to help ES recover from a primary shard failure
Global and local checkpoints
These are sequence numbers.
- A replication group has global checkpoints
- A replication shard has local checkpoints
This helps ES recover data with specific checkpoints. ES only needs to compare the delta between current state and checkpoints in shards and groups to get a shard back up to the right state.
Document versioning
_version metadata field is an integer that is incremented when modifying a document.
This is referred to as internal versioning
Optimistic concurrency control
This prevents overwriting documents inadvertently due to concurrent operations.
Example scenario:
Imagine a scenario where two customers retrieve product data at the same time, the first customer purchases the product and the stock count is updated in ES. The second customer does the same, but updates the stock count thinking the "live" value is the same as it was when it was retrieved, when in fact it's 1 less due to the first customers purchase:
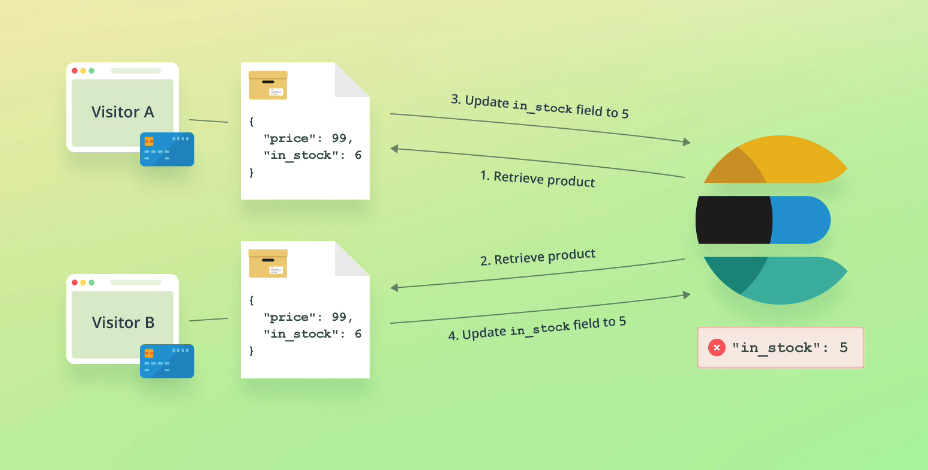
We need our second update to fail if the document has been modified since we retrieved it.
The old way
Of solving this problem involved sending down version numbers of documents:
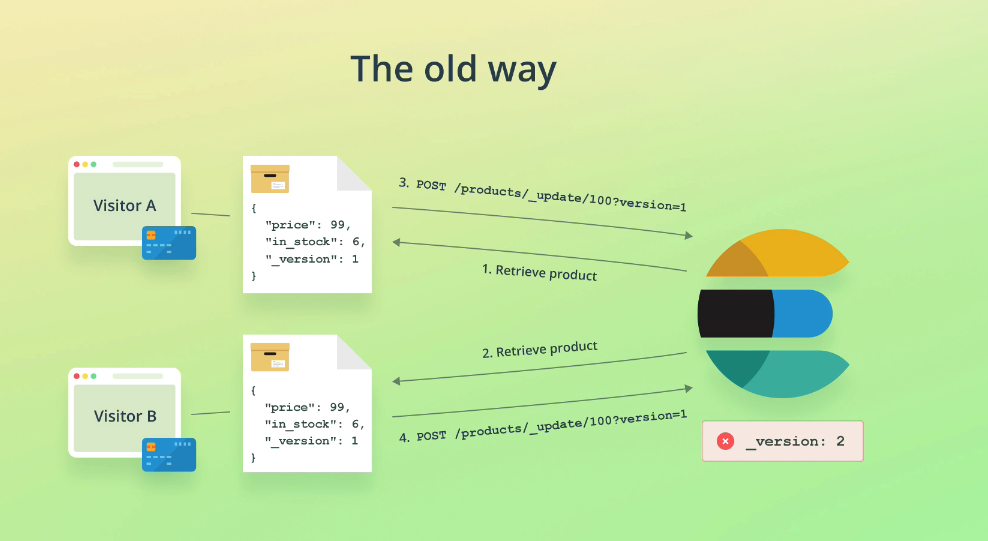
The new way
Uses primary terms and sequence numbers:
{
"_index": "products",
"_id": "ig5mHpgBorYWjN5fK4m0",
"_version": 6,
"_seq_no": 5, // here
"_primary_term": 4, // here
"found": true,
"_source": {
"name": "Coffee Maker",
"price": 64,
"in_stock": 8,
"tags": [
"electronics"
]
}
}
Primary terms and sequence numbers are returned in the results, which we can use for update request:
POST /products/_update/ig5mHpgBorYWjN5fK4m0?if_primary_term=4&if_seq_no=5
{
"doc": {
"in_stock": 7
}
}
The doc will only be update if the primary_term and seq_no no match the document in ES. This means updates can't happen if a doc has been updated in the time since we retrieved the product.
How to handle failures
After this failure you need to handle your own retries:
- Retrieve doc again
- Use
primary_termandseq_nofor new updates
The Bulk API and batch processing
The bulk API lets you run bulk operations on indices at once. The API uses NDJSON, which follows this convention:
- Operation on first line
- Request body on subsequent line
- Additional operations on next line and so on...
When using bulk ensure to:
- Set
Content-Type: application/x-ndjson - Each line must end with new line or new line character:
\nor\r\nincluding the last line! - If a single action fails, the other actions will proceed as normal
- Include optimistic concurrency control parameters as it's supported in the Bulk API
The Bulk API is useful when you have many write actions to perform at once, it is more performant as it reduces network round trips
It's useful for scripted updates, e.g loading large amounts of data
Batch index data
POST /_bulk
{"index": { "_index": "products", "_id": 200 }}
{ "name": "Espresso Machine", "price": 199, "in_stock": 5 }
{"create": { "_index": "products", "_id": 201 }}
{ "name": "Milk frother", "price": 149, "in_stock": 14}
Update and delete docs
POST /_bulk
{"update": {"_index": "products", "_id": 201}}
{"doc": {"price": 129}}
{"delete": {"_index": "products", "_id": 200}}
Target single index
If all your bulk operations are on the same index you can specify the index in the request endpoint:
POST /products/_bulk
{"update": {"_id": 201}}
{"doc": {"price": 129}}
{"delete": {"_id": 200}}
Analysis / text analysis
Docs: text analysis types of token analyzers
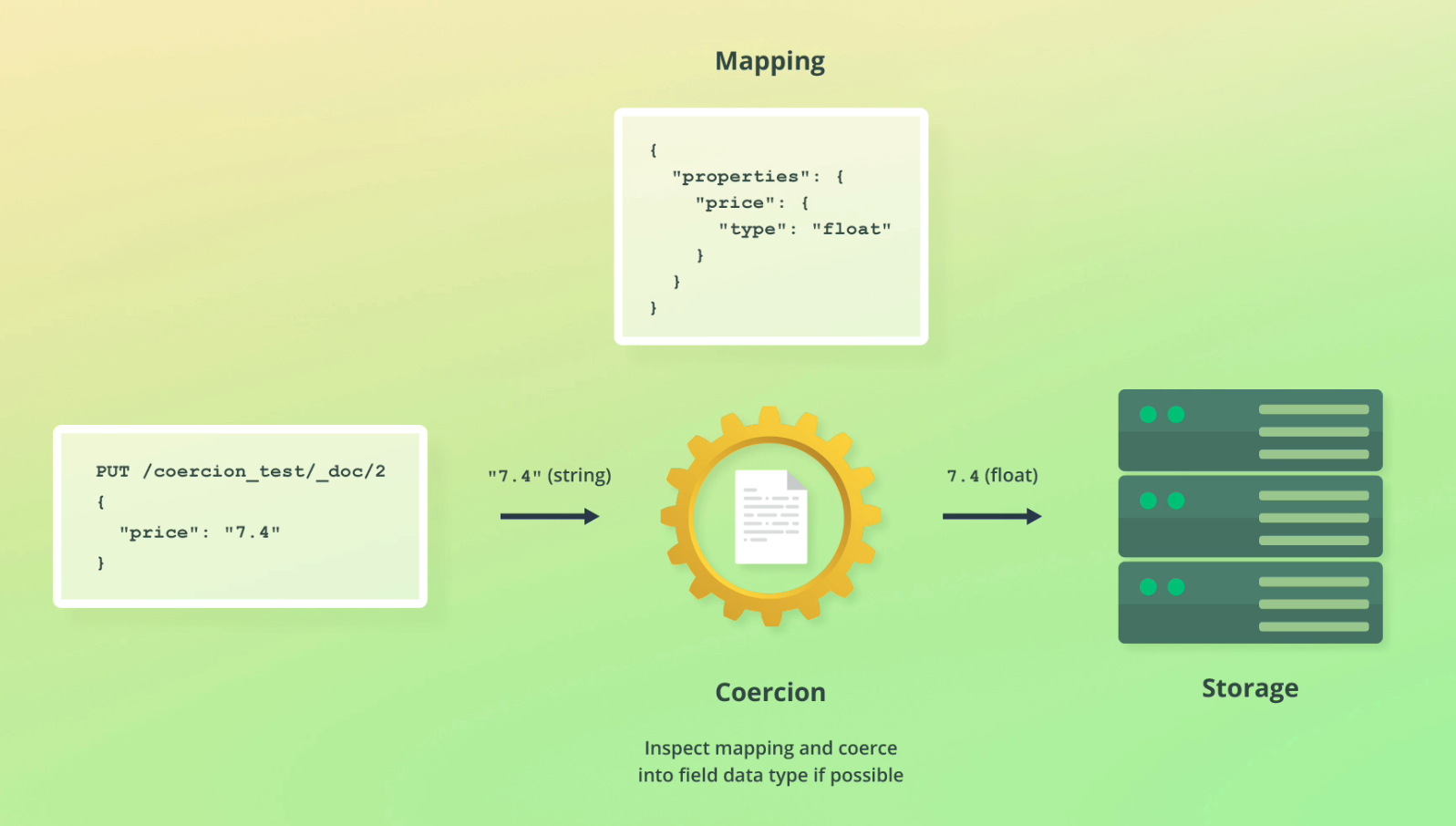
Text analysis is the process of taking raw input data and restructuring it for search optimisation.
In search engines this is usually referred to as tokenization and normalization.
ElasticSearch text analysis is comprised of three main steps: Character filters, tokenizer, token filters.
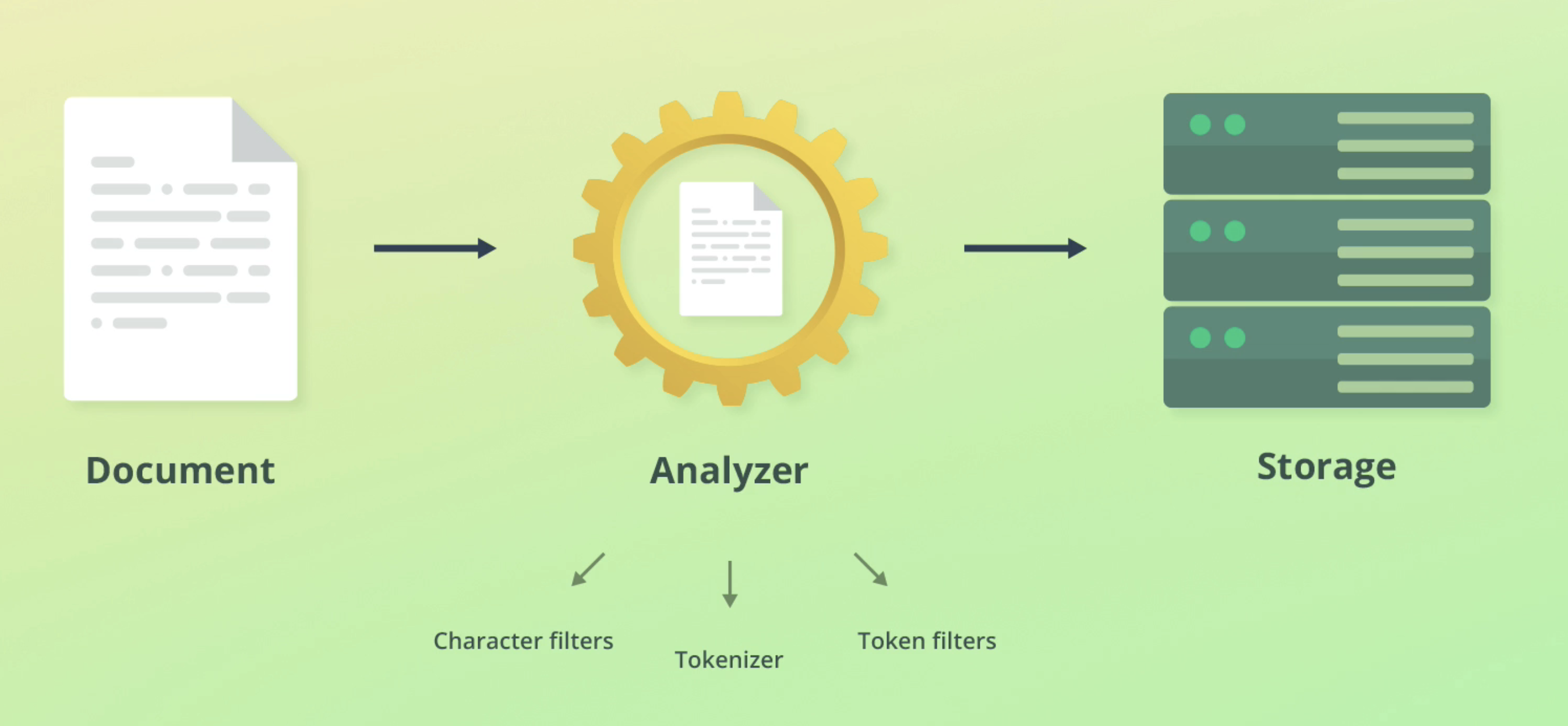
Character filters
Characters filters converts streams of text into unified formats. Examples include:
- Taking Hindu-Arabic numerals and convering into Arabic-Latin equivalents
- Stripping HTML from strings
Tokenizer
This splits strings into individual tokens (usually words) by using logical separators.
E.g "Quick brown fox!" -> ["Quick", "brown", "fox"]. It will also strip punctuation at this step.
Token filters
Adds, changes or removes tokens. For example lowercases Quick to quick.
You can use your own analyzers based on the above
Analyze API
The analyze API allows us to:
- Build custom analyzers
- Inspect what ES analysis is doing under the hood
Analyze text
POST /_analyze
{
"text": "2 guys walk into a bar, but the third... DUCKS!:-)",
"analyzer": "standard"
}
Response:
{
"tokens": [
{
"token": "2",
"start_offset": 0,
"end_offset": 1,
"type": "<NUM>",
"position": 0
},
{
"token": "guys",
"start_offset": 2,
"end_offset": 6,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "walk",
"start_offset": 7,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "into",
"start_offset": 12,
"end_offset": 16,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "a",
"start_offset": 18,
"end_offset": 19,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "bar",
"start_offset": 20,
"end_offset": 23,
"type": "<ALPHANUM>",
"position": 5
},
{
"token": "but",
"start_offset": 25,
"end_offset": 28,
"type": "<ALPHANUM>",
"position": 6
},
{
"token": "the",
"start_offset": 29,
"end_offset": 32,
"type": "<ALPHANUM>",
"position": 7
},
{
"token": "third",
"start_offset": 33,
"end_offset": 38,
"type": "<ALPHANUM>",
"position": 8
},
{
"token": "ducks",
"start_offset": 42,
"end_offset": 47,
"type": "<ALPHANUM>",
"position": 9
}
]
}
Under the hood, the analyzer parameter is comprised of 3 components:
char_filtertokenizerfilter
ES exposes these to us so we can build our own custom analyzers. See more here
Inverted Indices
In the analysers and analyzer API sections we saw how ES tokenizers data.
How ES stores this data is in an inverted index, which is a core search concept.
Remember that ES is built ontop of Lucene. Apache Lucene is actually the underlying tech that creates the inverted index
What is an inverted index?
An inverted index is a mapping between terms and the documents that contain them. The "terms" are really the tokens generated in ES' text analysis.
ES takes the following string: 2 guys walk into a bar, but the third... DUCKS!:-).
Performs text analysis on it (and thus tokenization) to output: ["2", "guys", "walk", "into", "a", "bar", "but", "the", "third", "ducks"].
This is then stored in an inverted index:
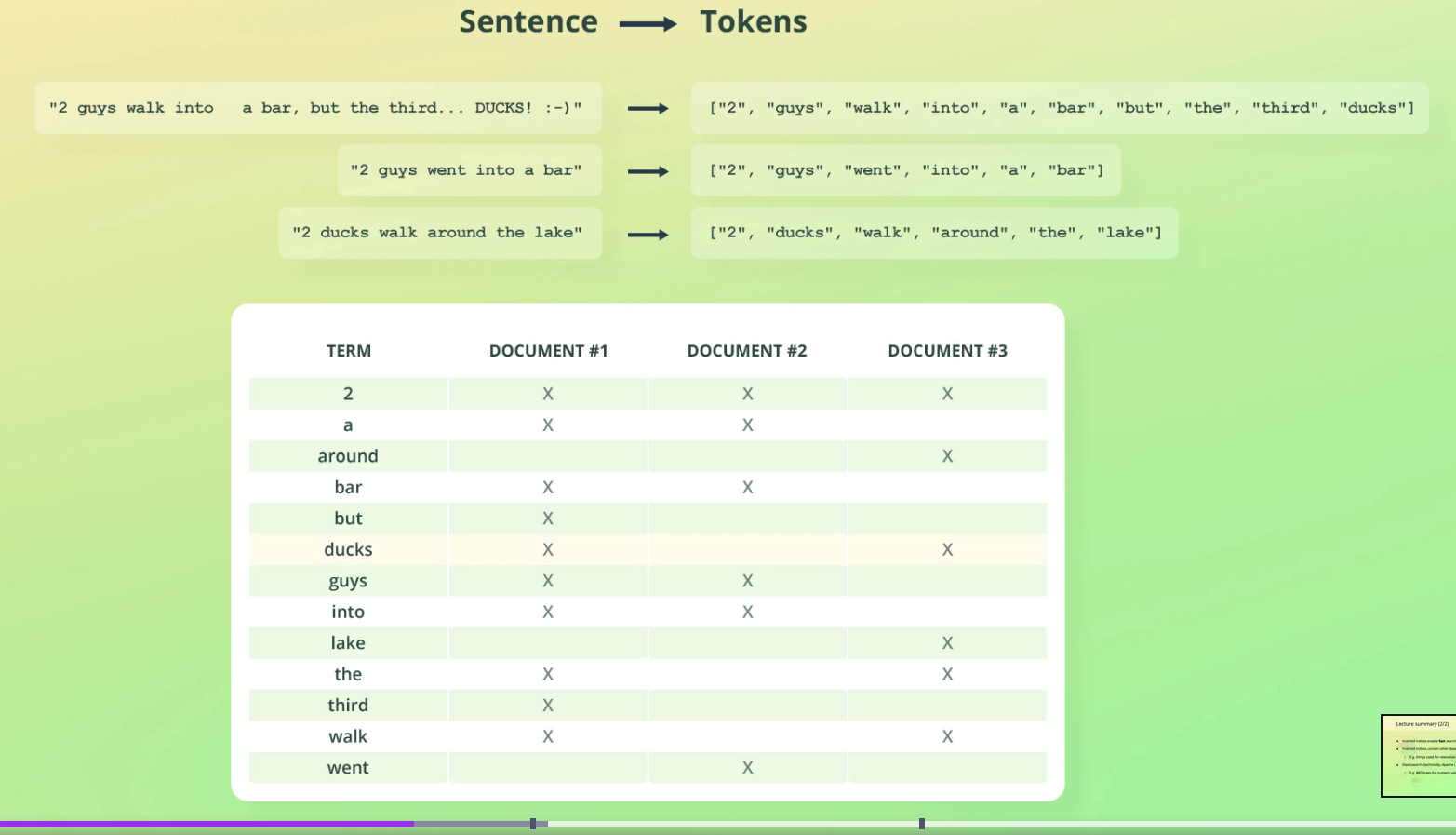
Inverted indexes allow fast search
Different inverted indices
When ES does text analysis it detects the data types of each token.
For example: 4 legged table! is processed as:
{
"tokens": [
{
"token": "4",
"start_offset": 0,
"end_offset": 1,
"type": "<NUM>",
"position": 0
},
{
"token": "legged",
"start_offset": 2,
"end_offset": 8,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "table",
"start_offset": 9,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 2
}
]
2 is detected as the NUM type, whereas table and legged are alphanumeric (ALPHANUM).
ES only creates inverted indices for text/alphanumeric/ALPHANUM fields.
Other data types are instead stored in a BKD tree.

Mapping
Mapping defines the structure of documents, ie their fields and their data types.
We can either:
- Define custom mappings, OR
- Let ES generate mappings for us
Data types
Available data types are here.
We have typical data types like text, float, integer, boolean etc. But there are specific data types in ES that power specific use cases that are of interest:
Object
Objects may be nested to form a hierarchy. Instead of defining the type, ES instead defines a properties for the object:

Arrays of objects
ES flattens arrays of objects, which can cause some issues.
E.g
{
"group" : "fans",
"user" : [
{
"first" : "John",
"last" : "Smith"
},
{
"first" : "Alice",
"last" : "White"
}
]
}
Is flattened to
{
"group" : "fans",
"user.first" : [ "alice", "john" ],
"user.last" : [ "smith", "white" ]
}
And we lose relationships between fields.
To solve this we can define the object type as Nested. Read more here.
Nested objects are hidden in the background
Keyword
keyword is used for exact value matching. This is used for filtering, sorting and aggregating docs.
We can't use keyword fields for full text search. For keyword fields, a different analyzer is used, called the "keyword" analyzer. This is a noop analyzer, meaning it just re-outputs the string as a single token. This is because it's intended for exact matching.
You can still configure the analyzer, however, for example to lowercase keyword fields.
If you want a field to be of both type keyword and text, you can achieve this using the fields mapping parameter.
Type coercion
With dynamic mapping, ES will do type coercion. For example the string "7.4" will be converted to a float.